Modele Językowe Wizji (VLM) rewolucjonizują dziedzinę analizy dokumentów, rozwiązując wiele ograniczeń inherentnych w tradycyjnych systemach Optycznego Rozpoznawania Znaków (OCR). Podczas gdy OCR był podstawową technologią do cyfryzacji tekstu z obrazów, napotyka znaczące wyzwania w złożonych scenariuszach. Należą do nich problemy z dokładnością w przypadku niskiej jakości obrazów, ograniczone zrozumienie kontekstu, trudności z mieszanymi językami oraz niemożność interpretacji elementów wizualnych. VLM oferują obiecujące rozwiązanie, łącząc zaawansowane komputerowe widzenie z możliwościami przetwarzania języka naturalnego. Artykuł ten bada, jak VLM pokonują niedociągnięcia OCR, oferując bardziej solidne i wszechstronne rozwiązania do przetwarzania dokumentów w erze cyfrowej.
Czym jest OCR? Jakie są procesy OCR w analizie dokumentów?
Optyczne Rozpoznawanie Znaków (OCR) to technologia, która umożliwia konwersję różnych typów dokumentów, takich jak zeskanowane dokumenty papierowe, pliki PDF czy obrazy uchwycone przez aparat cyfrowy, na edytowalne i przeszukiwalne dane. Proces ten jest kluczowy w przetwarzaniu dokumentów i wyodrębnianiu danych z PDF, umożliwiając maszynom rozpoznawanie wydrukowanych lub ręcznie pisanych znaków tekstowych w cyfrowych obrazach.
Proces OCR
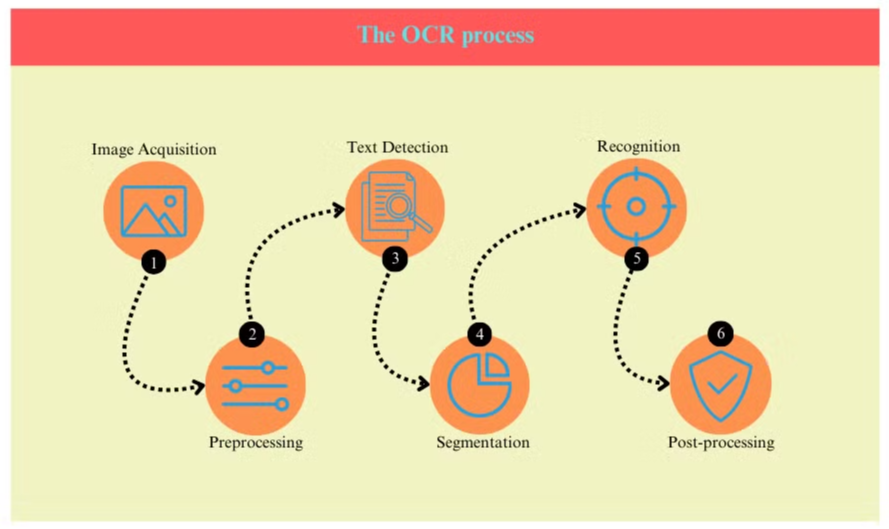
Proces OCR zazwyczaj obejmuje kilka kroków:
- Pozyskiwanie obrazu: Dokument jest skanowany lub fotografowany w celu utworzenia cyfrowego obrazu.
- Wstępne przetwarzanie: Obraz jest oczyszczany, usuwając szumy oraz dostosowując jasność i kontrast.
- Wykrywanie tekstu: System identyfikuje obszary zawierające tekst w obrazie.
- Segmentacja znaków: Poszczególne znaki są izolowane w obrębie obszarów tekstowych.
- Rozpoznawanie znaków: Każdy znak jest analizowany i porównywany z bazą danych znanych znaków.
- Post-processing: Rozpoznany tekst jest sprawdzany pod kątem błędów przy użyciu informacji lingwistycznych i kontekstowych.
Chociaż OCR znacznie poprawił zdolności analizy dokumentów, wciąż napotyka ograniczenia w obsłudze złożonych układów, niskiej jakości obrazów i zróżnicowanych czcionek. To właśnie tutaj zaawansowane technologie, takie jak modele językowe wizji, wkraczają, aby poprawić dokładność i zrozumienie w wyodrębnianiu danych z obrazów i dokumentów.
Ograniczenia tradycyjnej technologii OCR
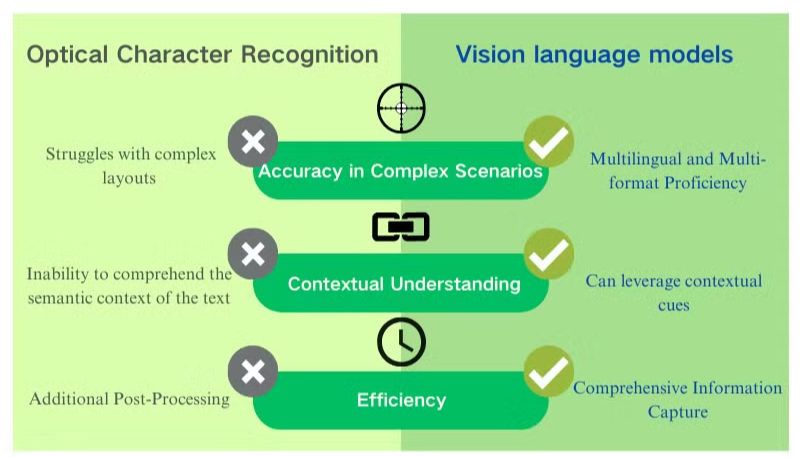
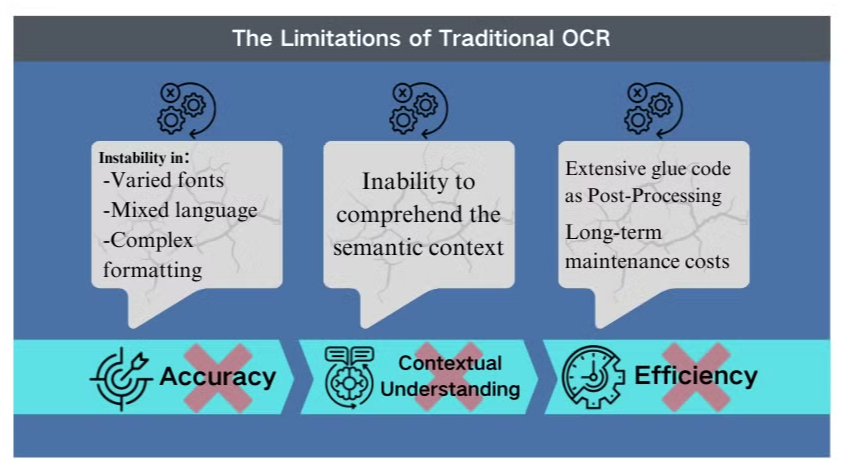
Wyzwania dokładności w złożonych scenariuszach
Tradycyjna technologia optycznego rozpoznawania znaków (OCR), mimo że korzystna dla podstawowego wyodrębniania tekstu, napotyka znaczące przeszkody w obliczu skomplikowanych układów dokumentów lub niskiej jakości obrazów. Systemy te często mają trudności z utrzymaniem dokładności podczas przetwarzania dokumentów z różnorodnymi czcionkami, mieszanymi językami lub złożonym formatowaniem. Na przykład, OCR może zawodzić podczas próby wyodrębnienia danych z prezentacji bogatych w obrazy lub gęsto formatowanych plików PDF.
Brak zrozumienia kontekstowego
Jednym z najbardziej oczywistych ograniczeń konwencjonalnego OCR jest jego niezdolność do zrozumienia semantycznego kontekstu przetwarzanego tekstu. To niedociągnięcie staje się szczególnie widoczne w scenariuszach wymagających subtelnej interpretacji, takich jak umowy prawne czy raporty medyczne. Skupienie OCR na rozpoznawaniu znaków bez świadomości kontekstowej może prowadzić do krytycznych błędów interpretacyjnych, szczególnie w przypadku niejednoznacznych znaków lub terminologii specyficznej dla branży.
Nieskuteczności w post-processingu
Ograniczenia OCR często wymagają znacznych wysiłków w post-processingu. Ten dodatkowy krok może znacznie zwiększyć czas i zasoby potrzebne do przetwarzania dokumentów. Ponadto tradycyjne systemy OCR zazwyczaj nie radzą sobie z wyodrębnianiem informacji z wykresów, tabel czy innych elementów nie-tekstowych, co dodatkowo komplikuje proces wyodrębniania dokumentów. Te nieskuteczności podkreślają potrzebę bardziej zaawansowanych rozwiązań, takich jak modele językowe wizji, które oferują bardziej kompleksowe podejście do analizy dokumentów i wyodrębniania danych.
Czym są modele językowe wizji i jak poprawiają OCR
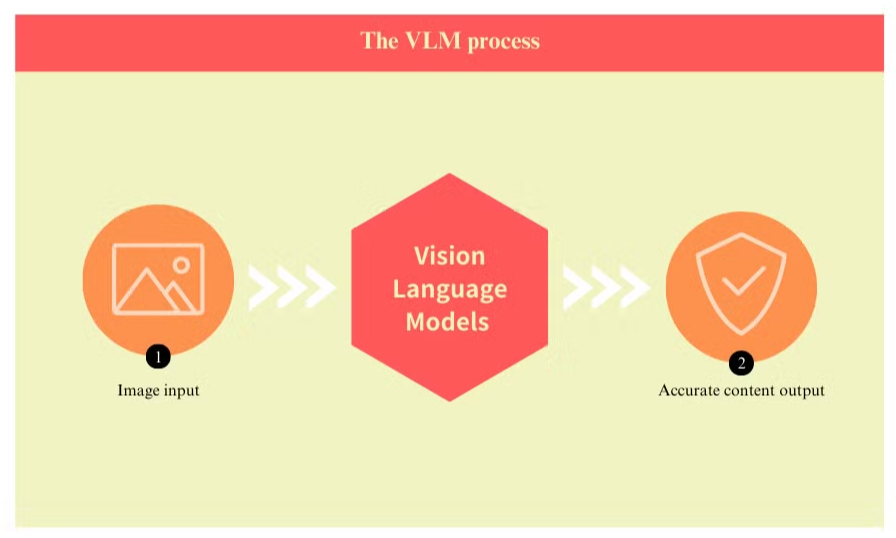
Modele językowe wizji stanowią znaczący krok naprzód w technologii przetwarzania dokumentów, rozwiązując wiele ograniczeń inherentnych w tradycyjnych systemach optycznego rozpoznawania znaków (OCR). Te zaawansowane modele łączą komputerowe widzenie z przetwarzaniem języka naturalnego, aby jednocześnie zrozumieć zarówno elementy wizualne, jak i tekstowe dokumentów.
Zwiększona dokładność i zrozumienie kontekstu
W przeciwieństwie do OCR, który ma trudności z niską jakością obrazów i złożonymi układami, modele językowe wizji doskonale radzą sobie z interpretacją różnych formatów dokumentów. Mogą dokładnie wyodrębniać dane z obrazów, PDF-ów i innych treści wizualnych, nawet w obliczu trudnych scenariuszy. Ta poprawiona dokładność wynika z ich zdolności do uwzględniania całego kontekstu dokumentu, a nie skupiania się wyłącznie na poszczególnych znakach lub słowach.
Kompleksowe wyodrębnianie danych
Modele językowe wizji wykraczają poza proste rozpoznawanie tekstu, oferując kompleksowe możliwości wyodrębniania danych z PDF. Mogą identyfikować i interpretować tabele, wykresy i figury w dokumentach, zachowując integralność złożonych układów. To holistyczne podejście do analizy dokumentów umożliwia bardziej subtelne i pełne pozyskiwanie informacji, znacznie zwiększając użyteczność wyodrębnionych danych dla aplikacji downstream.
Biegłość w wielu językach i formatach
Jedną z kluczowych zalet modeli językowych wizji jest ich elastyczność w obsłudze wielu języków i formatów dokumentów. W przeciwieństwie do systemów OCR, które mogą mieć trudności z nielatynskimi skryptami lub dokumentami w mieszanych językach, te modele mogą bezproblemowo przetwarzać treści w różnych językach i skryptach, co czyni je nieocenionymi dla globalnych potrzeb przetwarzania dokumentów.
Kluczowe korzyści modeli językowych wizji dla zrozumienia dokumentów
Modele językowe wizji oferują znaczące przewagi w porównaniu do tradycyjnego OCR w zakresie przetwarzania dokumentów i wyodrębniania danych. Te systemy oparte na AI łączą zrozumienie wizualne i tekstowe, aby dostarczyć lepsze wyniki w różnych typach dokumentów.
Zwiększona dokładność i zrozumienie kontekstowe
Modele językowe wizji doskonale radzą sobie z obsługą złożonych układów, niskiej jakości obrazów i różnorodnych czcionek. W przeciwieństwie do OCR, który ma trudności z niejednoznacznymi znakami, te modele wykorzystują wskazówki kontekstowe do dokładnej interpretacji tekstu. Ta zdolność dramatycznie poprawia dokładność wyodrębniania danych z PDF, szczególnie w przypadku dokumentów o skomplikowanej strukturze lub słabej jakości obrazu.
Kompleksowe pozyskiwanie informacji
Podczas gdy OCR koncentruje się wyłącznie na rozpoznawaniu tekstu, modele językowe wizji mogą wyodrębniać dane z obrazów, tabel i wykresów. To holistyczne podejście zapewnia, że kluczowe informacje nie są pomijane podczas fazy przetwarzania dokumentów. Poprzez uchwycenie zarówno elementów tekstowych, jak i wizualnych, te modele zapewniają pełniejsze zrozumienie treści dokumentów.
Biegłość w wielu językach i formatach
Modele językowe wizji wykazują niezwykłą elastyczność w przetwarzaniu dokumentów w różnych językach i formatach. Mogą bezproblemowo obsługiwać dokumenty w mieszanych językach i nielatynskich skryptach, pokonując znaczące ograniczenie tradycyjnych systemów OCR. Ta wszechstronność czyni je nieocenionymi dla globalnych przedsiębiorstw zajmujących się różnorodnymi typami dokumentów i języków.
Zastosowania w rzeczywistym świecie, które umożliwiły VLM, a które OCR zawiodło
Modele językowe wizji rewolucjonizują przetwarzanie dokumentów w finansach, zasobach ludzkich i innych sektorach, rozwiązując krytyczne ograniczenia tradycyjnych systemów OCR. Te zaawansowane modele AI przekształcają wysiłki na rzecz cyfrowej transformacji w różnych branżach, oferując lepszą dokładność i zrozumienie kontekstowe.
Rewolucjonizowanie przetwarzania dokumentów finansowych
Modele językowe wizji przekształcają przetwarzanie dokumentów w finansach, pokonując ograniczenia tradycyjnego OCR. Te zaawansowane modele doskonale radzą sobie z wyodrębnianiem danych z złożonych sprawozdań finansowych, faktur i paragonów o skomplikowanych układach. W przeciwieństwie do OCR, potrafią zrozumieć kontekst, dokładnie interpretując niejednoznaczne znaki (np. odróżniając zero od litery O) oraz mieszane języki często występujące w globalnych dokumentach finansowych.
Udoskonalanie operacji HR poprzez inteligentną analizę dokumentów
W sektorze HR modele językowe wizji okazują się nieocenione w wyodrębnianiu danych z PDF z CV, akt pracowniczych i ocen wydajności. Te modele potrafią zrozumieć semantyczną strukturę dokumentów, umożliwiając dokładniejsze pozyskiwanie i analizę informacji. Ta zdolność znacznie usprawnia procesy rekrutacyjne i zarządzanie danymi pracowników, zadania, w których OCR często ma trudności z różnorodnymi formatami i ręcznymi notatkami.
Poprawa zgodności i zarządzania ryzykiem
Modele językowe wizji są szczególnie skuteczne w zakresie zgodności i zarządzania ryzykiem zarówno w finansach, jak i HR. Mogą wyodrębniać i interpretować kluczowe informacje z dokumentów regulacyjnych, umów i polityk z większą dokładnością niż OCR. Ta ulepszona zdolność przetwarzania dokumentów zapewnia lepsze przestrzeganie wymogów prawnych i bardziej efektywne procedury oceny ryzyka.
Podsumowanie
Podsumowując, modele językowe wizji stanowią znaczący krok naprzód w technologii przetwarzania dokumentów, rozwiązując wiele inherentnych ograniczeń tradycyjnych systemów OCR. Łącząc zrozumienie wizualne i tekstowe, te zaawansowane modele oferują lepszą wydajność w szerokim zakresie trudnych scenariuszy, od złożonych układów po mieszane języki i niską jakość obrazów. W miarę jak organizacje kontynuują cyfryzację swoich operacji i poszukują bardziej efektywnych sposobów na wyodrębnienie wartości z swoich repozytoriów dokumentów, modele językowe wizji stają się potężnym narzędziem zarówno dla programistów, jak i liderów inżynieryjnych. Ich zdolność do zrozumienia kontekstu, obsługi różnorodnych formatów i dostarczania dokładniejszych wyników pozycjonuje je jako kluczowy element w zaawansowanych pipeline'ach RAG i możliwościach wyszukiwania w całym przedsiębiorstwie, ostatecznie napędzając inicjatywy cyfrowej transformacji na nowe wyżyny.