Czy kiedykolwiek zastanawiałeś się, co oznacza skrót OCR? Rozpoznawanie Optyczne Znaków to potężna technologia, która przekształca obrazy tekstu w dane zrozumiałe dla maszyn. Choć OCR oferuje ogromne korzyści w zakresie digitizacji dokumentów i ekstrakcji informacji, nie jest wolne od wad. Zgłębiając tę technologię, kluczowe jest zrozumienie zarówno jej możliwości, jak i ograniczeń. W tym artykule odkryjesz znaczenie OCR oraz przyjrzysz się jego potencjalnym wadom. Zyskując kompleksowe zrozumienie Rozpoznawania Optycznego Znaków, będziesz lepiej przygotowany do określenia, czy i jak wdrożyć tę technologię w swoich procesach i projektach.
Co oznacza OCR i czym jest OCR?
Co oznacza OCR?
OCR oznacza Rozpoznawanie Optyczne Znaków, technologię, która umożliwia komputerom rozpoznawanie i przekształcanie różnych typów dokumentów. W swojej istocie, OCR to proces skanowania wydrukowanego lub odręcznego tekstu i konwertowania go na tekst zakodowany maszynowo. Umożliwia to łatwe przeszukiwanie, edytowanie i przenoszenie tekstu. Zrozumienie, co oznacza OCR, jest niezbędne dla każdego, kto pracuje z technologiami skanowania dokumentów i rozpoznawania tekstu.
Czym jest OCR?
Dla tych, którzy nie są zaznajomieni z tym terminem, "czym jest OCR" to powszechne pytanie, odnoszące się do Rozpoznawania Optycznego Znaków, technologii, która pozwala komputerom odczytywać tekst z obrazów lub zeskanowanych dokumentów.
OCR przekształca wydrukowany lub odręczny tekst w dane zrozumiałe dla maszyn, łącząc świat papierowy z cyfrowymi formatami. Technologia ta wykorzystuje zaawansowane algorytmy do wykrywania kształtów liter, struktur słów, a nawet całych zdań. Dzięki temu przekształca statyczne obrazy w edytowalne i przeszukiwalne pliki tekstowe.
Technologia OCR opiera się zasadniczo na technologii widzenia komputerowego i rozpoznawania wzorców. OCR to proces skanowania dokumentów lub obrazów zawierających tekst i wykorzystania zaawansowanych algorytmów do identyfikacji i konwersji tekstu na cyfrowy, edytowalny format. Jednym z kluczowych momentów w historii technologii OCR był rok 1974, kiedy Ray Kurzweil opracował system OCR omni-font, który potrafił rozpoznawać tekst w praktycznie dowolnej czcionce. Na przestrzeni lat OCR ewoluowało od prostego dopasowywania szablonów do bardziej zaawansowanych systemów.
Pomimo swoich możliwości, technologia OCR obecnie napotyka pewne ograniczenia. Należą do nich trudności w rozpoznawaniu tekstu w obrazach o słabej jakości, problemy z obsługą złożonych układów lub tła oraz różna dokładność w przypadku różnych czcionek, języków lub pisma odręcznego. Dodatkowo, systemy OCR mogą mieć trudności z dokumentami, które mają kolorowe tła, są rozmyte lub przekrzywione oraz z pismem odręcznym.
Zrozumienie oprogramowania do rozpoznawania optycznego znaków
Oprogramowanie do rozpoznawania optycznego znaków to transformacyjna technologia, która przekształca różne typy dokumentów w edytowalne i przeszukiwalne dane. Odgrywa kluczową rolę w digitizacji naszego świata, czyniąc informacje bardziej dostępnymi i zarządzalnymi. Oprogramowanie OCR wykorzystuje zaawansowany proces do konwersji obrazów tekstu na dane zrozumiałe dla maszyn.
Jak działa oprogramowanie OCR
1. Pozyskiwanie obrazu
Podróż OCR zaczyna się od uchwycenia obrazu dokumentu. Może to być zrealizowane za pomocą skanera lub aparatu cyfrowego. Obraz jest następnie tłumaczony na format cyfrowy, który komputer może przetworzyć.
2. Wstępne przetwarzanie i poprawa obrazu
Drugi krok polega na poprawie jakości obrazu. Po pozyskaniu obrazu, przechodzi on wstępne przetwarzanie, aby poprawić jego jakość dla lepszego rozpoznawania. Ten krok może obejmować dostosowanie kontrastu, jasności i ostrości obrazu, a także usunięcie wszelkich szumów lub nieistotnych elementów. Ten etap wstępnego przetwarzania jest kluczowy dla uzyskania dokładnych wyników, zwłaszcza w przypadku niskiej jakości skanów lub fotografii.
3. Wykrywanie tekstu
Oprogramowanie OCR analizuje wstępnie przetworzony obraz, aby wykryć obszary zawierające tekst. Robi to, szukając wzorców i kształtów charakterystycznych dla tekstu, takich jak linie o różnych grubościach i wysokościach.
4. Segmentacja znaków
Gdy obszary tekstu są wykryte, oprogramowanie dzieli tekst na mniejsze jednostki, takie jak bloki, linie, słowa lub nawet pojedyncze znaki. Oprogramowanie OCR analizuje obraz piksel po pikselu, aby zidentyfikować wzory tworzące znaki. Dzieli obraz na mniejsze segmenty, izolując każdy znak.
5. Rozpoznawanie i ekstrakcja tekstu
Następnie oprogramowanie porównuje te izolowane kształty z ogromną bazą danych znanych wzorców znaków, aby określić, co każdy znak oznacza. Oprogramowanie wyodrębnia cechy z znaków, takie jak liczba linii, krzywizn czy kątów. Te cechy pomagają OCR rozpoznać i odróżnić różne znaki.
6. Post-processing
Po zidentyfikowaniu znaków, system OCR przechodzi przez etap post-processingu, w którym koryguje wszelkie potencjalne błędy i formatuje tekst do wyjścia. Skorygowany tekst jest następnie eksportowany do pożądanego formatu, takiego jak dokument Word lub przeszukiwalny PDF.
Przykłady zastosowań oprogramowania do rozpoznawania optycznego znaków
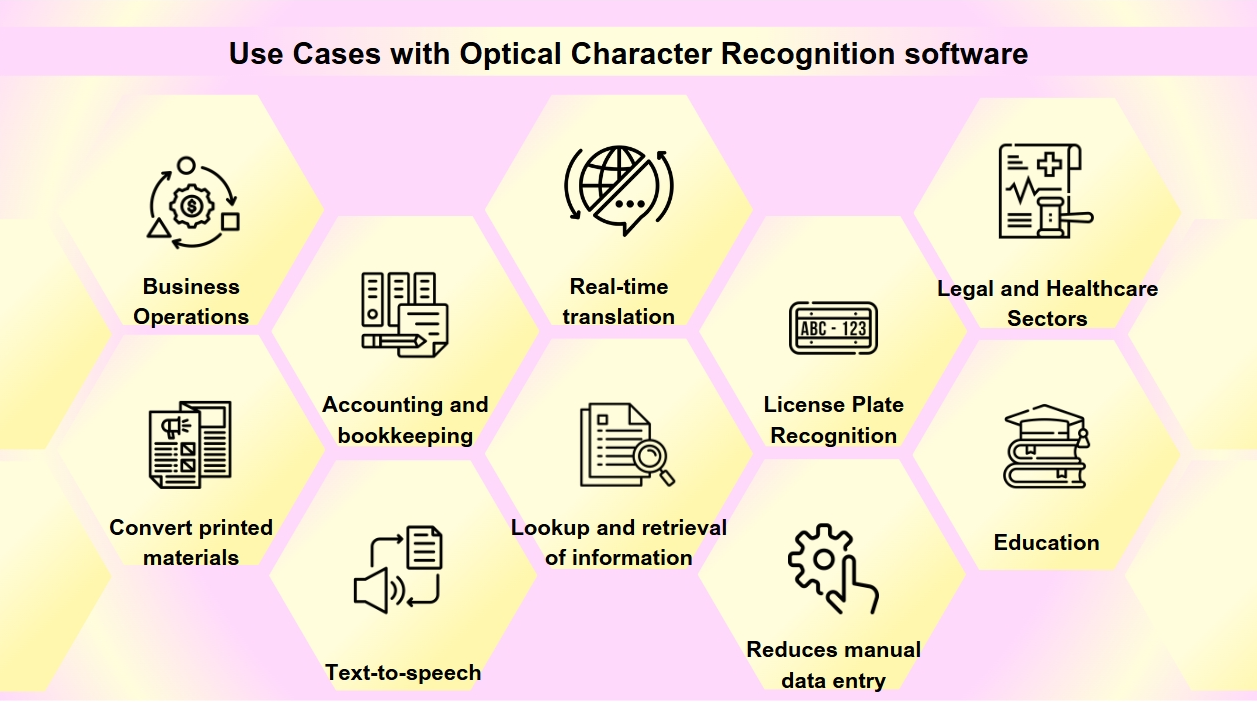
OCR stało się niezbędnym narzędziem w cyfrowej transformacji wielu branż, usprawniając procesy i poprawiając dostępność oraz dokładność danych. Możesz spotkać OCR częściej, niż myślisz. Od skanowania wizytówek po digitizację starych książek, OCR odgrywa kluczową rolę w różnych branżach. Technologia OCR ma szeroki zakres zastosowań:
-
Digitizacja dokumentów: OCR jest używane do przekształcania materiałów drukowanych, takich jak stare książki, gazety i dokumenty historyczne, w formaty cyfrowe, co czyni je przeszukiwalnymi i zachowuje je dla przyszłych pokoleń.
-
Przetwarzanie formularzy: Firmy wykorzystują OCR do automatycznego wyodrębniania danych z formularzy, co zmniejsza ręczne wprowadzanie danych i zwiększa efektywność w różnych sektorach, takich jak finanse i opieka zdrowotna.
-
Przetwarzanie faktur: Technologia OCR może odczytywać tekst na fakturach i automatycznie wprowadzać dane do systemów finansowych, usprawniając procesy księgowe i rachunkowe.
-
Dostępność: OCR umożliwia funkcjonalność tekst-na-mowę, tworząc wersje audio tekstu dla osób niewidomych, co czyni materiały drukowane bardziej dostępnymi.
-
Aplikacje mobilne: OCR jest zintegrowane z aplikacjami do zadań takich jak skanowanie wizytówek, rozpoznawanie tekstu na zdjęciach i ułatwianie tłumaczenia w czasie rzeczywistym.
-
Przeszukiwalność: OCR zwiększa przeszukiwalność zeskanowanych dokumentów, wyodrębniając tekst z obrazów lub PDF-ów, co umożliwia łatwe wyszukiwanie i odzyskiwanie informacji.
-
Rozpoznawanie tablic rejestracyjnych: Używane do zarządzania parkingiem i ruchem drogowym, OCR może rozpoznawać tablice rejestracyjne, umożliwiając efektywne monitorowanie i egzekwowanie.
-
Operacje biznesowe: OCR usprawnia procesy biznesowe, automatyzując wprowadzanie danych z dokumentów takich jak faktury, paragony i zamówienia, a także przyspieszając rekrutację poprzez skanowanie i przetwarzanie aplikacji o pracę i CV.
-
Sektory prawny i zdrowotny: Kancelarie prawne wykorzystują OCR do digitizacji akt spraw i dokumentów prawnych w celu łatwiejszego odzyskiwania informacji, podczas gdy dostawcy opieki zdrowotnej wykorzystują go do przekształcania rekordów pacjentów i formularzy medycznych w elektroniczne rekordy zdrowotne (EHR), poprawiając zarządzanie danymi i opiekę nad pacjentami.
-
Edukacja: W środowiskach edukacyjnych OCR jest używane do tworzenia cyfrowych podręczników i materiałów edukacyjnych, poprawiając dostępność dla uczniów o różnych potrzebach i wspierając inkluzywne środowisko nauki.
W miarę jak technologia OCR się rozwija, nadal odgrywa kluczową rolę w czynieniu informacji bardziej dostępnymi i efektywnymi w obsłudze w erze cyfrowej.
Wady OCR: Ograniczenia i niedogodności
Wyzwania dokładności
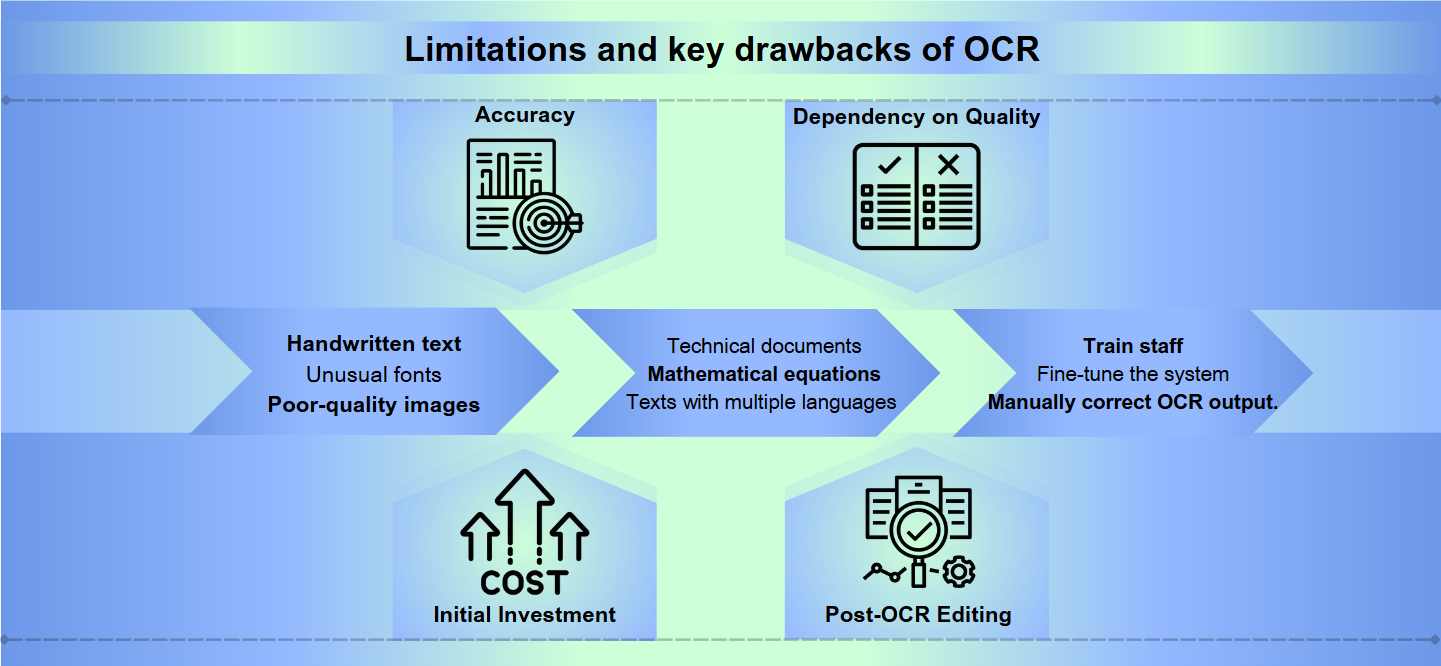
Chociaż technologia Rozpoznawania Optycznego Znaków (OCR) przeszła długą drogę, nadal napotyka znaczne przeszkody w osiągnięciu idealnej dokładności. Tekst odręczny, nietypowe czcionki lub obrazy o słabej jakości mogą prowadzić do błędnych interpretacji i pomyłek. Nawet niewielkie różnice w kształcie lub rozmiarze znaków mogą wprowadzać zamieszanie w systemach OCR, co skutkuje zniekształconym wynikiem, który wymaga ręcznej korekty.
Ograniczenia językowe i formatowe
Większość rozwiązań OCR doskonale radzi sobie z standardowymi językami i formatami, ale ma trudności z treściami specjalistycznymi. Dokumenty techniczne, równania matematyczne lub teksty w wielu językach mogą stanowić znaczące wyzwania. Dodatkowo, OCR może zawodzić w obliczu złożonych układów, tabel lub dokumentów o skomplikowanej formatacji, co może prowadzić do utraty kluczowych informacji strukturalnych.
Intensywność zasobów
Wdrażanie i utrzymanie skutecznego systemu OCR może być intensywne pod względem zasobów. Wysokiej jakości oprogramowanie OCR często wiąże się z dużymi kosztami, a sprzęt potrzebny do przetwarzania dużych wolumenów dokumentów może być kosztowny. Ponadto czas i wysiłek potrzebne do szkolenia personelu, dostosowywania systemu oraz ręcznego przeglądania i korygowania wyników OCR mogą obciążać zasoby organizacji.
Kluczowe wady OCR
-
Dokładność: Oprogramowanie OCR może mieć trudności z dokładnością, zwłaszcza w przypadku obrazów o słabej jakości, złożonych układów lub tekstu odręcznego. Błędy mogą obejmować odczytywanie znaków w sposób błędny lub pomijanie całych sekcji tekstu.
-
Zależność od jakości: Skuteczność OCR jest w dużej mierze uzależniona od jakości oryginalnego dokumentu. Wyblakły tusz, smugi lub pogniecione kartki mogą prowadzić do niedokładnych tłumaczeń.
-
Początkowa inwestycja: Ustawienie systemu OCR może wymagać znacznych kosztów początkowych, w tym nie tylko oprogramowania, ale także kompatybilnego sprzętu, takiego jak skanery.
-
Edycja po OCR: Często wyniki procesów OCR wymagają ręcznego przeglądu i korekty, co może być czasochłonne.
Model językowy wizji przezwyciężający ograniczenia OCR
W miarę postępu technologii pojawiają się innowacyjne rozwiązania, które mają na celu rozwiązanie niedociągnięć tradycyjnego Rozpoznawania Optycznego Znaków (OCR). Jednym z takich przełomów jest Model Językowy Wizji (VLM), który łączy widzenie komputerowe i przetwarzanie języka naturalnego, rewolucjonizując ekstrakcję tekstu i jego zrozumienie.
Zwiększone zrozumienie kontekstu
VLM-y doskonale radzą sobie z rozumieniem kontekstu otaczającego tekst, w przeciwieństwie do izolowanego rozpoznawania znaków przez OCR. Analizując elementy wizualne obok tekstu, te modele mogą interpretować złożone układy, odręczne notatki, a nawet częściowo zasłonięty tekst z niezwykłą dokładnością.
Wielojęzyczne i multimodalne możliwości
Podczas gdy OCR często ma trudności z różnorodnymi językami i skryptami, VLM-y wykazują imponującą wszechstronność. Mogą płynnie przetwarzać wiele języków i nawet interpretować treści wizualne, takie jak diagramy czy wykresy, zapewniając bardziej kompleksowe zrozumienie dokumentów.
Adaptacyjne uczenie się i ciągłe doskonalenie
W przeciwieństwie do statycznych systemów OCR, VLM-y wykorzystują uczenie maszynowe, aby dostosowywać się i poprawiać w miarę upływu czasu. Gdy napotykają nowe dane i scenariusze, te modele udoskonalają swoje działanie, stając się coraz lepsze w obsłudze różnych typów i formatów dokumentów.
Przezwyciężając ograniczenia OCR, Modele Językowe Wizji torują drogę do dokładniejszego, efektywniejszego i inteligentniejszego przetwarzania dokumentów w różnych branżach.
Wybierz Model Językowy Wizji: Wypróbuj AnyParser
Opierając się na postępach Modeli Językowych Wizji (VLM), AnyParser wyróżnia się jako zaawansowane rozwiązanie, które przekracza ograniczenia tradycyjnej technologii OCR. Opracowane przez zespół CambioML, AnyParser to potężne narzędzie do analizy dokumentów, które wykorzystuje precyzyjne i konfigurowalne API do wyodrębniania informacji z różnych nieustrukturyzowanych źródeł danych, takich jak PDF-y, obrazy i wykresy, przekształcając je w strukturalne formaty.
Podstawa techniczna i możliwości
AnyParser opiera się na solidnej podstawie dużych modeli językowych (LLM), zapewniając wysoką dokładność w ekstrakcji tekstu, tabel, wykresów i układów z dokumentów. Wyróżnia się zdolnością do zachowania oryginalnego układu i formatu, co jest szczególnie korzystne w przypadku dokumentów o złożonych układach lub wymagających zachowania oryginalnej estetyki.
Prywatność i bezpieczeństwo
Podkreślając prywatność użytkowników, AnyParser przetwarza dane lokalnie, co chroni wrażliwe informacje. Ta funkcja jest znaczącą zaletą dla przedsiębiorstw i osób zajmujących się poufnymi danymi.
Możliwość dostosowania i elastyczność
Oferując wysoki stopień konfigurowalności, AnyParser pozwala użytkownikom ustalać niestandardowe zasady ekstrakcji i definiować formaty wyjściowe, które odpowiadają ich specyficznym potrzebom. Ta elastyczność czyni go idealnym narzędziem do szerokiego zakresu zastosowań, od inżynierii AI po analizę finansową.
Podsumowanie
Jak się dowiedziałeś, technologia OCR oferuje potężne możliwości digitizacji tekstu, ale nie jest wolna od ograniczeń. Choć rozpoznawanie optyczne znaków może dramatycznie poprawić efektywność, musisz starannie rozważyć potencjalne wady. Weź pod uwagę problemy z dokładnością, wyzwania formatowania i wymagania dotyczące zasobów przed wdrożeniem rozwiązania OCR. Ostatecznie decyzja o wykorzystaniu OCR zależy od Twoich specyficznych potrzeb i okoliczności. Zrozumienie zarówno korzyści, jak i wad pozwoli Ci podjąć świadomą decyzję, czy OCR jest odpowiednie dla Twojej organizacji. W miarę jak OCR nadal ewoluuje, bądź na bieżąco z nowymi osiągnięciami, które mogą rozwiązać obecne niedociągnięcia i odblokować jeszcze większy potencjał tej transformacyjnej technologii.
Wezwanie do działania
Wykorzystaj moc Modeli Językowych Wizji, próbując AnyParser za darmo, aby przekształcić swoje PDF-y w Google Sheets na https://www.cambioml.com/sandbox. Uzyskaj darmową konsultację na temat tego, jak VLM-y mogą poprawić Twój proces ekstrakcji danych.