Czym są dane strukturalne i niestrukturalne
W erze informacji cyfrowych dane są generowane w każdym momencie, a przedsiębiorstwa tworzą wartość poprzez analizę i przetwarzanie danych. Dlatego zbieranie i rejestrowanie danych oraz przetwarzanie i analiza danych stały się dwoma ważnymi zadaniami w działalności biznesowej. W procesie zbierania danych coraz częściej napotyka się dane niestrukturalne, których źródło i forma są różnorodne, co utrudnia ich klasyfikację lub wyszukiwanie. Efektywne przetwarzanie danych jest niezbędne dla organizacji, aby skutecznie przekształcać surowe dane w użyteczne informacje. W procesie przetwarzania danych częściej spotyka się dane strukturalne, które mają wyraźną strukturę, dobrze zdefiniowane informacje i mogą być łatwo organizowane, wyszukiwane i analizowane. Dlatego przekształcenie danych niestrukturalnych w dane strukturalne jest ważnym krokiem dla przedsiębiorstw w celu wykorzystania wartości danych.
Dane strukturalne
Dane strukturalne to dane, które pasują do zdefiniowanego modelu danych lub schematu. Są szczególnie przydatne w przypadku danych dyskretnych, numerycznych, takich jak operacje finansowe, dane sprzedażowe i marketingowe oraz modelowanie naukowe.
Dane strukturalne są zazwyczaj ilościowe i zorganizowane w sposób, który umożliwia łatwe wyszukiwanie. Obejmuje to powszechne typy, takie jak imiona, adresy, numery kart kredytowych, numery telefonów, oceny gwiazdkowe, informacje bankowe i inne dane, które można łatwo zapytać za pomocą SQL w relacyjnych bazach danych.
Przykłady danych strukturalnych w rzeczywistych zastosowaniach obejmują dane o lotach i rezerwacjach podczas rezerwacji lotu oraz zachowania i preferencje klientów w systemach CRM, takich jak Salesforce. Najlepiej nadają się do powiązanych zbiorów dyskretnych, krótkich, nieciągłych wartości numerycznych i tekstowych i są używane do kontroli zapasów, systemów CRM i systemów ERP.
Dane strukturalne są przechowywane w relacyjnych bazach danych, bazach danych grafowych, bazach danych przestrzennych, kostkach OLAP i innych. Ich największą zaletą jest to, że łatwiej je organizować, czyścić, wyszukiwać i analizować, ale głównym wyzwaniem jest to, że wszystkie dane muszą pasować do określonego modelu danych.
Dane niestrukturalne
Dane niestrukturalne to dane bez podstawowego modelu, który pozwala na rozróżnienie atrybutów. Używa się ich, gdy dane nie pasują do formatu danych strukturalnych, takich jak monitorowanie wideo, dokumenty firmowe i posty w mediach społecznościowych.
Przykłady danych niestrukturalnych obejmują różnorodne formaty, takie jak e-maile, obrazy, pliki wideo, pliki audio, posty w mediach społecznościowych, pliki PDF i inne. Około 80-90% danych jest niestrukturalnych, co oznacza, że mają ogromny potencjał na przewagę konkurencyjną, jeśli firmy potrafią je wykorzystać.
Przykłady danych niestrukturalnych w rzeczywistych zastosowaniach obejmują chatboty wykonujące analizę tekstu, aby odpowiadać na pytania klientów i dostarczać informacji oraz dane używane do przewidywania zmian na giełdzie w celu podejmowania decyzji inwestycyjnych. Dane niestrukturalne najlepiej nadają się do powiązanych zbiorów danych, obiektów lub plików, w których atrybuty zmieniają się lub są nieznane, i są używane z oprogramowaniem do prezentacji lub edycji tekstu oraz narzędziami do przeglądania lub edytowania mediów. Niestrukturalne dane usług dodatkowych, takie jak posty w mediach społecznościowych i opinie klientów, mogą dostarczać cennych informacji po przekształceniu w strukturalne formaty.
Zazwyczaj są przechowywane w jeziorach danych, bazach danych NoSQL, hurtowniach danych i aplikacjach. Największą zaletą danych niestrukturalnych jest ich zdolność do analizy danych, które nie mogą być łatwo przekształcone w dane strukturalne, ale głównym wyzwaniem jest to, że mogą być trudne do analizy. Główna technika analizy danych niestrukturalnych różni się w zależności od kontekstu i używanych narzędzi.
Różnica między danymi strukturalnymi a niestrukturalnymi
Zalety danych strukturalnych i wady danych niestrukturalnych
Dane strukturalne oferują zaletę łatwego wyszukiwania i wykorzystania w algorytmach uczenia maszynowego, co czyni je dostępnymi dla firm i organizacji do interpretacji danych. Istnieje również więcej narzędzi dostępnych do analizy danych strukturalnych niż danych niestrukturalnych. Z drugiej strony, dane niestrukturalne wymagają od naukowców zajmujących się danymi posiadania wiedzy w zakresie przygotowywania i analizy danych, co może ograniczać dostęp innych pracowników w organizacji. Dodatkowo, specjalne narzędzia są potrzebne do obsługi danych niestrukturalnych, co dodatkowo przyczynia się do ich braku dostępności.
Analiza danych strukturalnych a analiza danych niestrukturalnych
Analiza danych strukturalnych jest zazwyczaj prostsza, ponieważ dane są ściśle sformatowane, co pozwala na użycie logiki programowania do wyszukiwania i lokalizowania konkretnych wpisów danych, a także do tworzenia, usuwania lub edytowania wpisów. Ułatwia to automatyzację zarządzania danymi i analizę danych strukturalnych. W przeciwieństwie do tego, analiza danych niestrukturalnych nie ma zdefiniowanych atrybutów, co utrudnia wyszukiwanie i organizowanie. Analiza danych niestrukturalnych często wymaga złożonych algorytmów do wstępnego przetwarzania, manipulacji i analizy, co stanowi większe wyzwanie w procesie analizy. Analiza niestrukturalnych danych usług dodatkowych często wymaga zaawansowanych technik analizy, aby wydobyć znaczące informacje.
Zarządzanie danymi strukturalnymi a zarządzanie danymi niestrukturalnymi
Zarządzanie danymi strukturalnymi jest zazwyczaj bardziej efektywne ze względu na ich zorganizowany i przewidywalny charakter. Komputery, struktury danych i języki programowania mogą łatwiej rozumieć dane strukturalne, co prowadzi do minimalnych wyzwań w ich użyciu. Z kolei zarządzanie danymi niestrukturalnymi stawia dwa istotne wyzwania: przechowywanie, ponieważ zarządzanie danymi niestrukturalnymi zazwyczaj wymaga większego przetwarzania niż zarządzanie danymi strukturalnymi, oraz analiza, ponieważ zarządzanie danymi niestrukturalnymi nie jest tak proste jak analiza zarządzania danymi strukturalnymi. Aby zrozumieć i zarządzać danymi niestrukturalnymi, systemy komputerowe muszą najpierw rozłożyć je na zrozumiałe komponenty, co jest bardziej skomplikowanym procesem.
Podsumowanie różnicy między danymi strukturalnymi a niestrukturalnymi
Dane strukturalne są zdefiniowane i wyszukiwalne, obejmując dane takie jak daty, numery telefonów i numery SKU produktów. Ułatwia to organizację, czyszczenie, wyszukiwanie i analizę w porównaniu do danych niestrukturalnych, które obejmują wszystko inne, co jest trudniejsze do skategoryzowania lub wyszukania, takie jak zdjęcia, filmy, podcasty, posty w mediach społecznościowych i e-maile. Jedno zdanie wyjaśniające różnicę między danymi strukturalnymi a niestrukturalnymi: Większość danych na świecie jest niestrukturalna, ale łatwość zarządzania i analizy danych strukturalnych daje im znaczną przewagę w zastosowaniach, gdzie dane można starannie zorganizować i szybko uzyskać dostęp.
Przykłady danych strukturalnych i niestrukturalnych
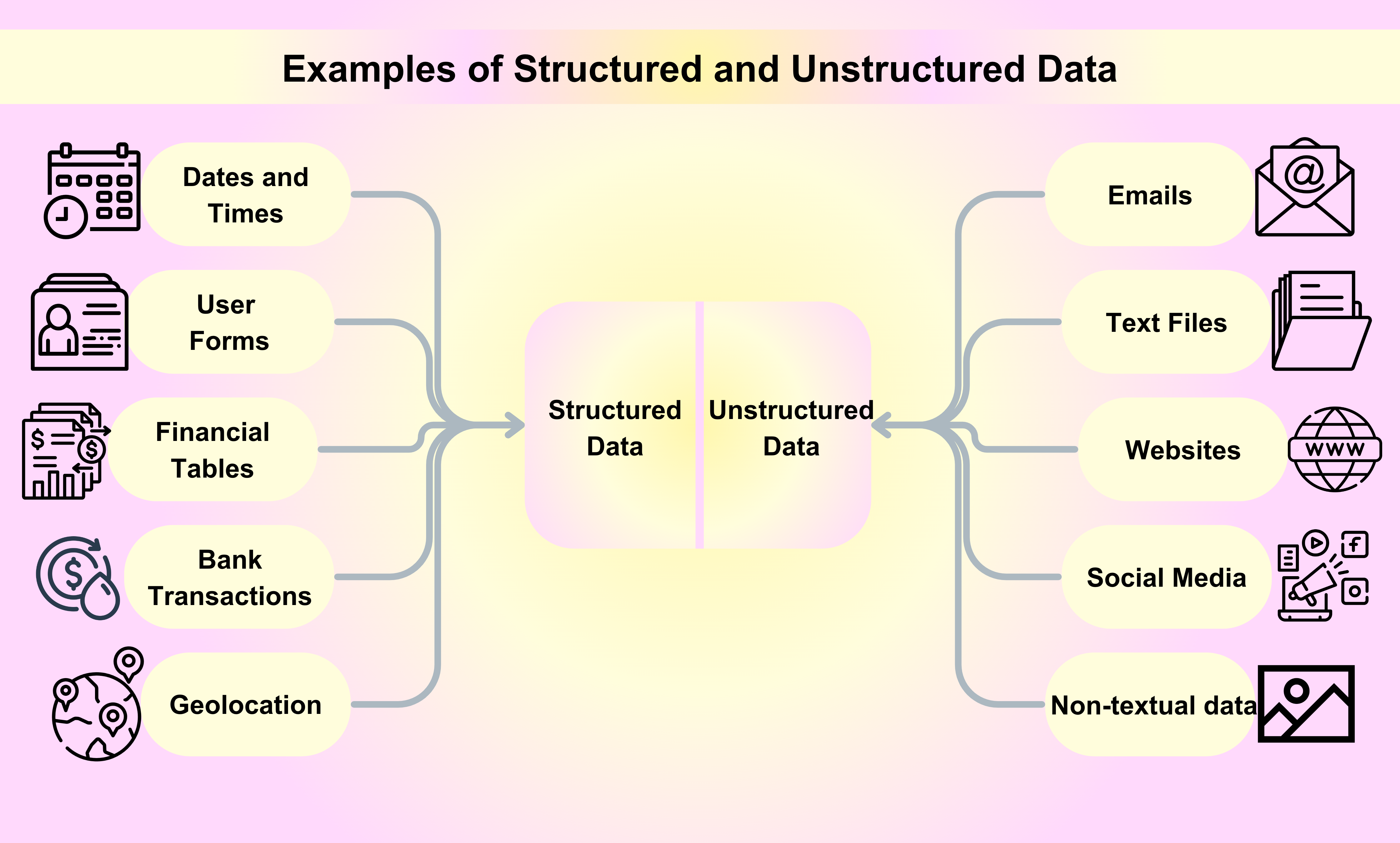
Przykłady danych strukturalnych
-
Daty i czasy: Daty i czasy mają określony format, co ułatwia ich odczyt i analizę przez maszyny. Na przykład, datę można sformatować jako YYYY-MM-DD, podczas gdy czas można sformatować jako HH:MM:SS.
-
Imiona klientów i informacje kontaktowe: Gdy zapisujesz się na usługę lub kupujesz produkt online, twoje imię, adres e-mail, numer telefonu i inne informacje kontaktowe są zbierane i przechowywane w zorganizowany sposób.
-
Transakcje finansowe: Transakcje finansowe, takie jak transakcje kartą kredytową, wpłaty bankowe i przelewy, to wszystko przykłady danych strukturalnych. Każda transakcja zawiera konkretne informacje w postaci numeru seryjnego, daty transakcji, kwoty i stron zaangażowanych.
-
Informacje o akcjach: Informacje o akcjach, takie jak ceny akcji, wolumeny handlowe i kapitalizacja rynkowa, są kolejnym przykładem danych strukturalnych. Te informacje są systematycznie organizowane i aktualizowane w czasie rzeczywistym.
-
Geolokalizacja: Dane geolokalizacyjne, w tym współrzędne GPS i adresy IP, są często używane w różnych aplikacjach, od systemów nawigacyjnych po kampanie marketingowe oparte na lokalizacji.
Przykłady danych niestrukturalnych
-
E-maile: E-maile są jednym z najpopularniejszych przykładów danych niestrukturalnych, które używamy na co dzień w celach biznesowych lub osobistych.
-
Pliki tekstowe: Przykłady danych niestrukturalnych obejmują pliki do przetwarzania tekstu, arkusze kalkulacyjne, pliki PDF, raporty i prezentacje.
-
Strony internetowe: Treści z takich stron jak YouTube, Instagram i Flickr są uważane za przykład danych niestrukturalnych.
-
Media społecznościowe: Dane generowane z platform mediów społecznościowych, takich jak Facebook, Twitter i LinkedIn, są przykładem danych niestrukturalnych.
-
Media: Cyfrowe obrazy, nagrania audio i filmy reprezentują ogromną ilość danych nie tekstowych w niestrukturalny sposób, które można uznać za przykłady danych niestrukturalnych.
Techniki analizy danych strukturalnych
-
Zapytania SQL: Dane strukturalne można efektywnie przeszukiwać za pomocą SQL (Structured Query Language), co pozwala na szybkie pobieranie i manipulowanie danymi przechowywanymi w relacyjnych bazach danych.
-
Hurtownie danych: Dane strukturalne mogą być przechowywane w hurtowniach danych, które integrują dane z wielu źródeł i wspierają złożone zapytania i analizy.
-
Algorytmy uczenia maszynowego: Algorytmy mogą łatwo przetwarzać dane strukturalne, aby identyfikować wzorce i dokonywać prognoz.
Dane strukturalne są łatwe do zrozumienia i manipulacji, co czyni je dostępnymi dla szerokiego kręgu użytkowników. Dane strukturalne umożliwiają efektywne przechowywanie, pobieranie i analizę, co przyspiesza proces podejmowania decyzji. Systemy danych strukturalnych mogą skalować się, aby obsługiwać duże wolumeny danych, zapewniając, że wydajność pozostaje wysoka w miarę wzrostu danych.
Techniki analizy danych niestrukturalnych
-
Przetwarzanie języka naturalnego (NLP): Techniki NLP są używane do analizy danych tekstowych, wydobywając znaczące informacje i spostrzeżenia z dużych wolumenów niestrukturalnego tekstu.
-
Uczenie maszynowe: Algorytmy uczenia maszynowego mogą być trenowane do rozpoznawania wzorców w danych niestrukturalnych, takich jak obrazy czy pliki audio.
-
Jeziora danych: Niestrukturalne dane mogą być przechowywane w jeziorach danych, które pozwalają na przechowywanie surowych danych w ich natywnej formie, dopóki nie będą potrzebne do analizy.
Z przykładu technik analizy danych niestrukturalnych wynika, że analiza danych niestrukturalnych jest bardziej skomplikowana i wymaga specjalistycznych narzędzi i technik. Przetwarzanie danych niestrukturalnych często wymaga znacznych zasobów obliczeniowych i pojemności przechowywania. Dane niestrukturalne mogą zawierać niespójności, błędy lub nieistotne informacje, co utrudnia zapewnienie jakości danych. Usprawnienie przetwarzania danych może znacząco zwiększyć zdolność organizacji do zarządzania i analizowania dużych wolumenów danych.
Przykłady potrzeby konwersji danych niestrukturalnych na dane strukturalne
-
Analiza opinii klientów: Przekształcenie recenzji i opinii klientów z niestrukturalnego tekstu w dane strukturalne pozwala firmom przeprowadzać analizę sentymentu i identyfikować trendy w satysfakcji klientów.
-
Rekordy medyczne: Strukturalizacja niestrukturalnych rekordów medycznych, takich jak notatki lekarzy i raporty obrazowe, umożliwia lepszą integrację z systemami elektronicznych rekordów zdrowotnych (EHR) i poprawia opiekę nad pacjentami.
-
Zgodność i raportowanie: Proces przetwarzania danych obejmuje wydobywanie, ładowanie i przekształcanie danych z różnych źródeł w format odpowiedni do analizy. Organizacje mogą potrzebować przekształcić dane niestrukturalne w strukturalne formaty, aby spełnić wymagania regulacyjne i ułatwić dokładne raportowanie.
-
Badania rynkowe: Przekształcenie danych niestrukturalnych z ankiet i grup fokusowych w dane strukturalne pomaga w analizie trendów rynkowych i zachowań konsumentów.
Jak AnyParser może przekształcić dane niestrukturalne w dane strukturalne
AnyParser, opracowany przez CambioML, to potężne narzędzie do analizy dokumentów zaprojektowane do wydobywania informacji z różnych źródeł danych niestrukturalnych, takich jak pliki PDF, obrazy i wykresy, i przekształcania ich w strukturalne formaty. Wykorzystuje zaawansowane modele językowe wizji (VLM), aby osiągnąć wysoką dokładność i efektywność w wydobywaniu danych.
Kluczowe cechy
-
Precyzja: Dokładnie wydobywa tekst, liczby i symbole, zachowując oryginalny układ i format.
-
Prywatność: Przetwarza dane lokalnie, aby zapewnić ochronę prywatności użytkowników i wrażliwych informacji.
-
Konfigurowalność: Umożliwia użytkownikom definiowanie niestandardowych reguł wydobywania i formatów wyjściowych.
-
Wsparcie dla wielu źródeł: Obsługuje wydobywanie z różnych źródeł danych niestrukturalnych, w tym plików PDF, obrazów i wykresów.
-
Strukturalne wyjście: Przekształca wydobyte informacje w strukturalne formaty, takie jak Markdown, CSV lub JSON.
Kroki do przetwarzania danych niestrukturalnych za pomocą AnyParser
-
Prześlij swój dokument: Rozpocznij od przesłania pliku z danymi niestrukturalnymi (np. PDF, obraz) do interfejsu internetowego AnyParser. Możesz przeciągnąć i upuścić plik lub wkleić zrzut ekranu, aby szybko przetworzyć.
-
Wybierz opcje wydobywania: Wybierz typ danych, które chcesz wydobyć. Na przykład, jeśli potrzebujesz wydobyć tabele z pliku PDF, wybierz opcję "Tylko tabela".
-
Przetwórz dokument: Silnik API AnyParser przetworzy dokument, dokładnie wykrywając i wydobywając wymagane informacje. Narzędzie wykorzystuje zaawansowane techniki VLM do identyfikacji odpowiednich punktów danych i przekształcania ich w strukturalny format.
-
Podgląd i weryfikacja: Przejrzyj wydobyte dane za pomocą funkcji podglądu AnyParser. Porównaj początkowe wydobycie z oryginalnym dokumentem, aby zapewnić dokładność.
-
Pobierz lub eksportuj: Gdy będziesz zadowolony z wydobycia, pobierz plik z danymi strukturalnymi (np. CSV, Excel) lub eksportuj go bezpośrednio do platform, takich jak Google Sheets, w celu dalszej analizy.
Korzyści z używania AnyParser
-
Efektywność i dokładność: Automatyzuje zadania wydobywania danych, redukując wysiłek manualny i minimalizując błędy.
-
Bezpieczeństwo danych: Zapewnia, że wrażliwe informacje są przetwarzane lokalnie, zgodnie z normami prywatności danych.
-
Elastyczna personalizacja: Użytkownicy mogą dostosować parametry wydobywania i formaty wyjściowe do swoich specyficznych potrzeb.
-
Zwiększona koncentracja na analizie: Ułatwia wydobywanie danych, pozwalając profesjonalistom skupić się na bardziej wartościowej analizie.
Zastosowania
-
Inżynierowie AI: Wydobywają tekst i informacje o układzie z plików PDF, aby rozwijać i trenować modele AI.
-
Analitycy finansowi: Wydobywają dane numeryczne z tabel PDF do dokładnej analizy finansowej.
-
Naukowcy danych: Przetwarzają duże wolumeny niestrukturalnych dokumentów, aby odkrywać spostrzeżenia i trendy.
-
Przedsiębiorstwa: Automatyzują przetwarzanie i analizę różnych dokumentów, takich jak umowy i raporty, aby poprawić efektywność operacyjną.
Korzystając z AnyParser, użytkownicy mogą przekształcać złożone dane niestrukturalne w strukturalne, edytowalne pliki, płynnie integrując je w swoje procesy robocze w celu zwiększenia analizy i zarządzania danymi.
Podsumowanie
W erze cyfrowej przekształcanie danych niestrukturalnych w strukturalne formaty za pomocą narzędzi takich jak AnyParser jest kluczowe dla firm, aby odkrywać spostrzeżenia i zyskać przewagę konkurencyjną. AnyParser może być wykorzystywany do analizy niestrukturalnych danych usług dodatkowych, co ułatwia ich integrację z systemami inteligencji biznesowej. Usprawniając ten proces, organizacje mogą efektywnie wykorzystać pełny potencjał swoich danych, co prowadzi do lepszego podejmowania decyzji i planowania strategicznego.