Att konvertera komplexa PDF-filer till Markdown kan vara en utmaning. Det finns många open-source-bibliotek tillgängliga för att extrahera text från PDF, men när det kommer till PDF-filer som innehåller komplexa element som tabeller och diagram, faller resultaten ofta kort. Populära stora språkmodeller som GPT eller Claude kan hantera dessa uppgifter men tenderar att vara långsamma och ibland producera felaktiga utdata. Traditionella OCR-verktyg, även om de är effektiva för enklare dokument, har ofta svårt att upprätthålla den exakta strukturen och den semantiska betydelsen av det ursprungliga innehållet. Å andra sidan hallucinerar vision-språkmodeller ibland, vilket leder till felaktiga parseringsresultat. Denna blogg kommer att förklara vad "parse" betyder och detaljera resultaten av en jämförande analys av flera modeller med hjälp av flera metoder.
Vad betyder "parse"?
I sammanhanget av PDF-parsing hänvisar "parse" till processen att extrahera specifika data från en PDF-fil med hjälp av specialiserad programvara känd som en PDF-parser. En PDF-parser analyserar innehållet i ett PDF-dokument och identifierar element som text, bilder, typsnitt, layouter och till och med metadata. De extraherade uppgifterna kan sedan organiseras och exporteras till olika format som XML, JSON eller Excel/CSV, vilket kan användas för olika ändamål som dataanalys, dokumentation eller automatisering av arbetsflöden.
Att förstå vad "parse" betyder är avgörande för att utvärdera effektiviteten av en parserlösning, särskilt när man jämför olika verktyg för PDF till Markdown-konvertering, eftersom PDF-parsering involverar mer än bara enkel textutvinning—det kräver att man känner igen och upprätthåller dokumentets semantiska struktur.
Hur mäter vi kvaliteten på dessa parserlösningar?
Vi har definierat en serie ordnivåmetoder för att bedöma prestandan hos olika modeller, med fokus på nyckelfaktorer som:
-
Precision, Återkallande och F-Mått: Utvärdering av kvaliteten och fullständigheten av parseringen.
-
BLEU-poäng och ANLS: Användbara för att utvärdera språk- och layoutstruktur.
-
Editavstånd, Jensen-Shannon Divergens och Jaccardavstånd: Metoder specifika för OCR-domänen, särskilt hjälpsamma för att förstå noggrannheten i innehållsreproduktionen.
Vår vision-språkmodell, AnyParser, visar exceptionell prestanda, kombinerar hastighet och noggrannhet, särskilt på komplexa layouter med tabeller och semantiska element. AnyParser överträffar andra lösningar, med en hastighetsökning på 20x jämfört med modeller som GPT/Claude samtidigt som den uppnår högre noggrannhet.
En omfattande jämförelse av ledande parsermodeller
Statistiskt objekt
För att verkligen visa kapabiliteterna hos AnyParser genomförde vi en omfattande jämförelse mot ledande parsermodeller i branschen och välkända stora språkmodeller (LLMs). Vår utvärdering inkluderade:
1. Stora språkmodeller
- AnyParser
- OpenAI:s GPT-4o
- Googles Gemini 1.5 Pro
- Anthropics Claude 3.5 Sonett
2. OCR-baserade tjänster
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Resultatpresentation och analys
Experiment 1
Först genomför vi en serie rigorösa jämförelser av prestandan hos olika dokument-AI-modeller på över 5 metoder nedan: BLEU, Precision och återkallande, F-Mått och ANLS. Du kan hitta den matematiska definitionen av dessa metoder i bilagan.
De jämförda modellerna är: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAI och Azure-DocAI.
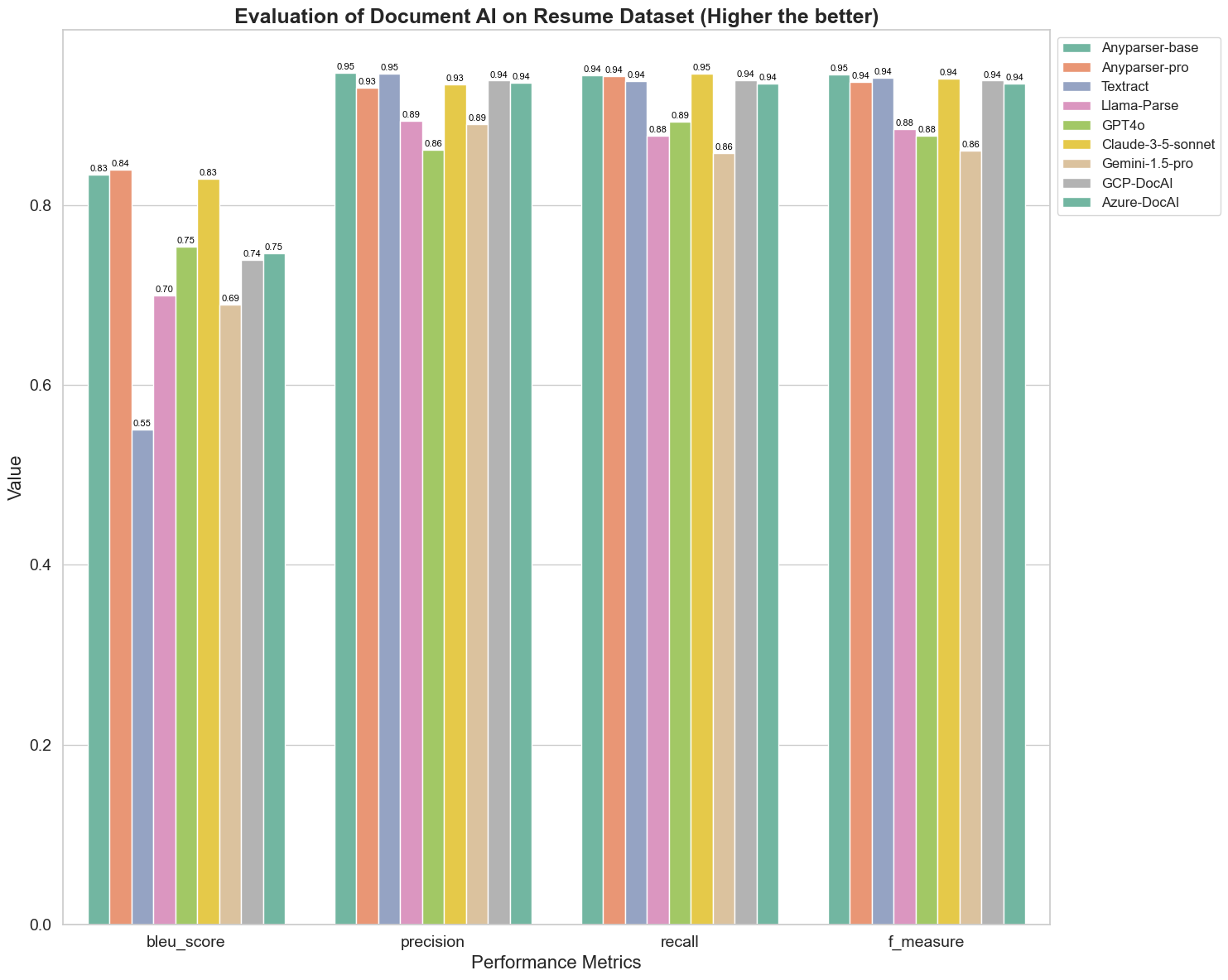
BLEU används som en bedömning av kvaliteten på tvåspråkig tolkning för att testa kvaliteten på modellerna i bearbetning av yttranden. Genom att jämföra resultaten av dessa parseringsmodeller under BLEU-bedömningsmetoden finner vi att: poängen för AnyParser-base och AnyParser-pro är betydligt högre än poängen för de andra modellerna, Amazon Textract får den lägsta poängen, och resultaten för de andra modellerna ligger på en relativt genomsnittlig nivå.
Igenkänningsnoggrannhet representeras vanligtvis av precision och återkallande, där precision representerar procentandelen av verkligt korrekta resultat bland de resultat som bedöms som korrekta av modellen, och återkallande representerar procentandelen av verkligt korrekt bedömda resultat av modellen bland alla faktiskt korrekta resultat. Genom att jämföra precision och återkallande hos dessa parseringsmodeller finner vi att: förutom Llama-Parse, GPT4o och Gemini-1.5-pro, ligger alla andra modeller på en hög nivå. Bland dem är AnyParser och Amazon Textract mer framträdande i precision, och AnyParser-base och AnyParser-pro är mer framträdande i återkallande. Den högre poängen för modellen på Precision indikerar att modellen producerar mer korrekt information i produktionsresultaten, och den högre poängen på återkallande indikerar att modellen har större kapacitet att få korrekt information från provet. Resultaten visar att AnyParser har en tydlig fördel när det gäller igenkänningsnoggrannhet för att extrahera text från PDF.
F-Mått är en omfattande utvärderingsindex av precision och återkallande på dessa två indikatorer. Genom att jämföra poängen för dessa parseringsmodeller under F-Mått kan vi se mer intuitivt att de fem modellerna, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI och Azure-DocAI, har en bättre styrka när det gäller igenkänningsnoggrannhet jämfört med andra modeller. Vi kan se mer intuitivt att de fem modellerna har mer styrka i igenkänningsnoggrannhet än de andra modellerna, och AnyParser har den högsta poängen under F-Mått, vilket ytterligare illustrerar den uppenbara fördelen med AnyParser i igenkänningsnoggrannhet för att extrahera text från PDF.
ANLS, som är en vanligt använd utvärderingsindex när det gäller att mäta noggrannheten och likheten mellan den ursprungliga texten och måltexten på teckennivå, är också mycket informativ för att mäta parseringsnivån hos modellerna. De högre poängen för AnyParser-base, AnyParser-pro och Azure-DocAI återspeglar den högre parseringsnivån hos dessa modeller jämfört med de andra modellerna.
Sammanfattningsvis överträffar AnyParser-base och AnyParser-pro de andra modellerna.
Experiment 2
Vi jämför också prestandan hos olika dokument-AI-modeller på tre olika metoder: Editavstånd, Jensen-Shannon Divergens och Jaccardavstånd. Metoderna används för att mäta likheten mellan modellernas utdata och ett referensdokument. Lägsta värden indikerar bättre prestanda.
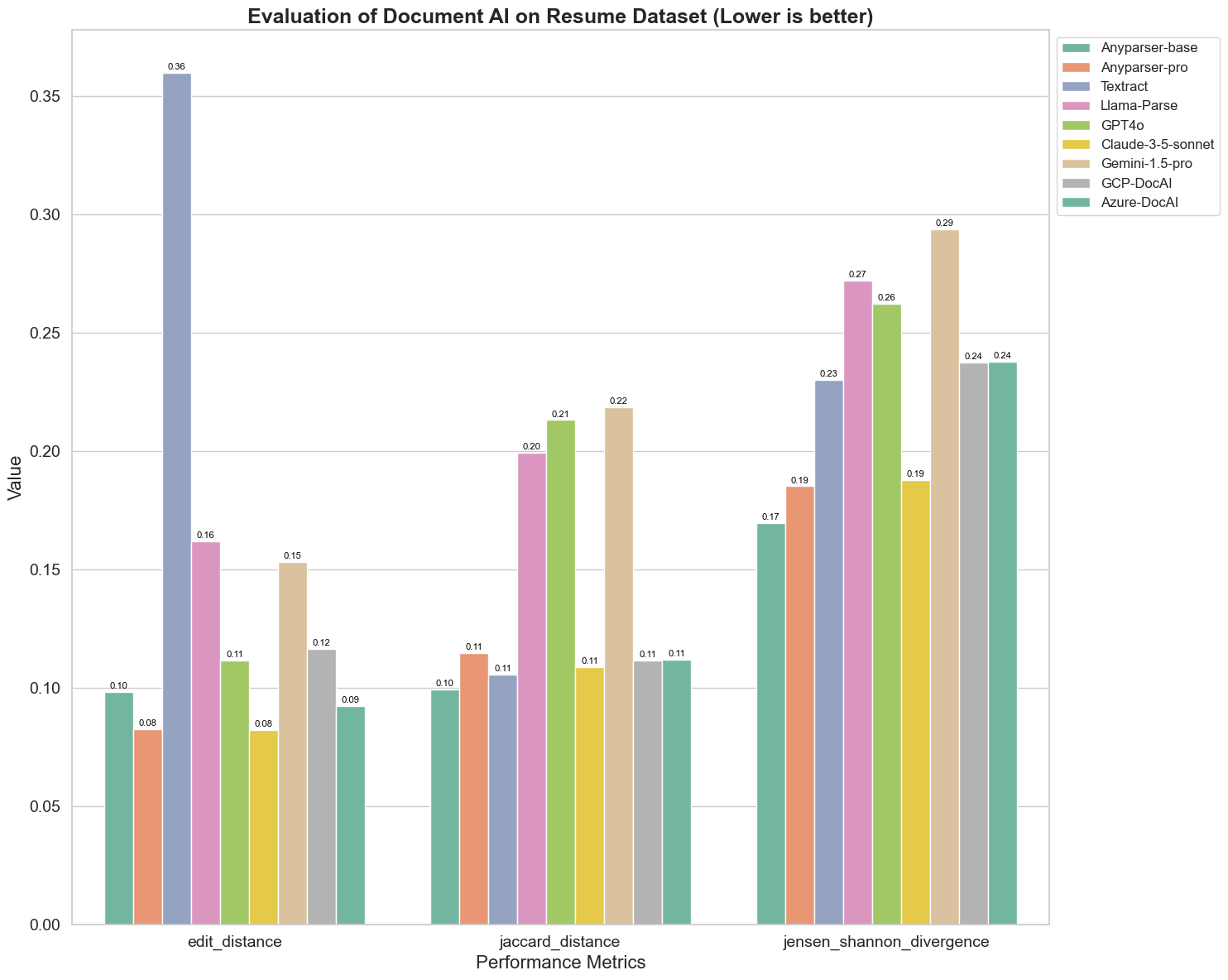
Här är några viktiga observationer från diagrammet:
-
Editavstånd: Modellerna AnyParser-base och AnyParser-pro presterar bäst med det lägsta editavståndet, vilket tyder på att deras utdata var närmast referensdokumentet.
-
Jensen-Shannon Divergens: Modellerna AnyParser-base och AnyParser-pro har den lägsta divergensen, vilket innebär att deras utdata är mest lika referensdokumentet när det gäller orddistribution.
-
Jaccardavstånd: Förutom Llama-Parse, GPT4O och Gemini-1.5, presterar alla andra modeller bra med det lägsta Jaccardavståndet, vilket indikerar att deras utdata har den högsta överlappningen med referensdokumentet när det gäller uppsättningen av använda ord.
Slutsats
Sammanfattningsvis tyder våra rigorösa tester på att AnyParser-base och AnyParser-pro generellt presterar bra över olika metoder, vilket indikerar dess potential för noggrann dokumentbearbetning. Från diagrammen kan vi se att traditionella OCR-modeller som den kända Amazon Textract får mycket lägre poäng än vision-språkmodeller. Men prestandan hos olika modeller varierar beroende på den använda metoden, vilket framhäver vikten av att överväga flera utvärderingskriterier när man jämför AI-modeller.
Introduktion av vår open-source utvärderingspipeline
För att effektivisera utvärderingar har vi skapat en utvärderingspipeline som erbjuder en branschstandardmetod för att jämföra parsermodeller. I vårt exempel visar vi dess användning inom HR-området, där CV-parsering är vanligt. Vi byggde en mångsidig syntetisk dataset av 128 CV, genererade med hjälp av parade bild-Markdown-filer. Med hjälp av GPT-4 genererade vi HTML-innehåll, renderade det till bilder och använde den extraherade texten som grund för jämförelse.
Och här är den bästa delen: vi har open-sourcat detta utvärderingsramverk på GitHub! Oavsett om du är utvecklare eller affärsanvändare, gör vår pipeline det möjligt för dig att utvärdera och jämföra parserkvaliteten hos olika modeller på din egen dataset.
Hitta snabbstartguiden i Github-repo och se hur olika parsermodeller står sig mot varandra. Vi tror att genom att visa styrkan hos vår modell öppet kan vi attrahera fler användare som vill ha pålitliga, snabba och noggranna parseringsmöjligheter.
Bilaga - Metoder
1. Precision
Precision mäter noggrannheten hos det parserade innehållet och visar hur många av de hämtade elementen som var korrekta. Vid parsering är det andelen korrekt extraherade ord av alla extraherade ord.
Precision = Sanna Positiva (TP) / (Sanna Positiva (TP) + Falska Positiva (FP))
- Sanna Positiva (TP): Ord som korrekt identifierats av parsern.
- Falska Positiva (FP): Ord som felaktigt identifierats av parsern.
2. Återkallande
Återkallande indikerar fullständigheten av parseringen, eller hur många relevanta ord från det ursprungliga dokumentet som hämtades.
Återkallande = Sanna Positiva (TP) / (Sanna Positiva (TP) + Falska Negativa (FN))
- Falska Negativa (FN): Ord i det ursprungliga dokumentet som missades av parsern.
3. F-Mått (F1-poäng)
F1-poängen är det harmoniska medelvärdet av Precision och Återkallande, vilket balanserar båda metoderna för att ge ett övergripande mått på parseringskvalitet.
F1-poäng = 2 × (Precision × Återkallande) / (Precision + Återkallande)
4. BLEU-poäng (Bilingual Evaluation Understudy)
BLEU-poängen mäter likheten mellan det parserade innehållet och den ursprungliga texten, med särskild betoning på ordens ordning. Den är särskilt användbar för att utvärdera språk- och strukturkonsistens i parserade dokument, eftersom den straffar utdata som skiljer sig i sekvens från den ursprungliga.
5. ANLS (Genomsnittlig Normaliserad Levenshtein Likhet)
ANLS kvantifierar likheten mellan det parserade innehållet och den ursprungliga, med hjälp av normaliserat editavstånd. Det beräknas genom att ta genomsnittet av den Normaliserade Levenshtein Likheten (NLS) för varje ordpar i de parserade och referenstexterna. NLS beräknas enligt följande:
NLS = 1 - (Levenshtein Avstånd (LD)(parserat ord, ursprungligt ord)) / max(Längd av parserat ord, Längd av ursprungligt ord)
Sedan är ANLS genomsnittet av NLS över alla ordpar:
ANLS = (1/N) × Σ(NLS_i) för i=1 till N
6. Editavstånd
Editavstånd beräknar antalet ordnivåoperationer (insättningar, borttagningar, substitutioner) som krävs för att konvertera den parserade texten till den ursprungliga.
7. Jensen-Shannon Divergens
Jensen-Shannon Divergens mäter likheten mellan diskreta sannolikhetsfördelningar av parserade och ursprungliga ordantal, vilket framhäver skillnader i ordets frekvens.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
där M = (1/2)(P + Q), och KL(P || Q) är Kullback-Leibler-divergens
8. Jaccardavstånd
Jaccardavstånd mäter olikheten mellan uppsättningar av ord i parserat och ursprungligt innehåll, användbart för att bedöma ordöverlappar.
Jaccardavstånd = 1 - |A ∩ B| / |A ∪ B|
där |A ∩ B| är antalet gemensamma element mellan A och B,
och |A ∪ B| är det totala antalet unika element i båda uppsättningarna.