Úvod
Tabulky jsou základem strukturované reprezentace dat, široce používané v oblastech jako finance, zdravotnictví a výzkum. Nicméně, extrakce tabulkových informací z formátů jako PDF, skenované dokumenty nebo obrázky zůstává výzvou kvůli různým rozvržením a složitostem.
Umělá inteligence (AI) revolucionalizovala zpracování dokumentů, což umožňuje přesná a efektivní řešení problémů, jako je například extrakce tabulky z PDF nebo převod tabulky PNG na strukturovaná data. Využitím pokročilých technik AI mohou nyní firmy snadno transformovat nestrukturované vizuály na akční poznatky, včetně převodu obrázku na tabulku pro bezproblémovou integraci do pracovních toků.
Tento blog zkoumá, jak AI extrakce tabulek posiluje průmyslová odvětví, zdůrazňuje základní technologie a ukazuje její potenciál zjednodušit složité úkoly zpracování dokumentů.

Výzvy v Tradiční Extrakci Tabulek
Ruční extrakce tabulkových dat z dokumentů jako PDF nebo obrázky je únavná, náchylná k chybám a neefektivní. Níže jsou uvedeny některé z běžných výzev, kterým čelí tradiční metody:
-
Složitá Struktura Tabulek: Tabulky často mají nepravidelná rozvržení, jako jsou vnořené buňky, vícerozměrné hlavičky nebo sloučené řádky, které jsou obtížné k interpretaci. Tradiční nástroje nedokážou přesně extrahovat tabulku z PDF v takových scénářích.
-
Různé Formáty: Tabulky se objevují v široké škále formátů, včetně skenovaných dokumentů, souborů PNG tabulek a PDF. Extrakce dat z těchto formátů vyžaduje pokročilé rozpoznávací techniky, které překračují jednoduché OCR.
-
Kontext a Význam: Tradiční systémy mají potíže s uchováním vztahů mezi řádky a sloupci, což je klíčové při převodu obrázku na tabulku nebo zpracování velkých datových sad.
Tyto výzvy zdůrazňují potřebu inteligentních řešení, jako je extrakce tabulek poháněná AI, která dokáže zvládat složitá rozvržení a různé formáty při zajištění vysoké přesnosti.
Co je AI Extrakce Tabulek?
AI extrakce tabulek je aplikace technik inteligentního zpracování dokumentů přizpůsobených k identifikaci, extrakci a organizaci strukturovaných dat z tabulek v různých formátech dokumentů. Na rozdíl od tradičních pravidlových metod, přístupy poháněné AI využívají pokročilé technologie k řešení složitých výzev, jako jsou nestandardní rozvržení, sloučené buňky a vícerozměrné hlavičky.
Klíčovým pokrokem v této oblasti je využití modelů Vision-Language (VLM). VLM kombinují sílu počítačového vidění a porozumění přirozenému jazyku, což jim umožňuje interpretovat jak vizuální, tak textové prvky v dokumentu. Tato dvojí schopnost umožňuje VLM:
- Vizualizovat struktury tabulek, i když postrádají explicitní formátování.
- Kontextově chápat obsah, například rozlišovat mezi hlavičkami, daty a poznámkami.
- Přizpůsobit se různým typům dokumentů, včetně skenovaných obrázků, PDF a ručně psaných poznámek.
Využitím VLM se AI extrakce tabulek stala přesnější a univerzálnější, schopná zpracovávat dokumenty v několika jazycích a extrahovat vztahy mezi datovými body, které tradiční metody často přehlížejí.
Klíčové Technologie za AI Extrakcí Tabulek
AI extrakce tabulek se spoléhá na soubor pokročilých technologií, které spolupracují na překonání tradičních výzev. Mezi nimi vynikají modely Vision-Language (VLM) jako transformační inovace. Níže je rozdělení klíčových technologií a zásadní role VLM:
-
Optické Rozpoznávání Znaku (OCR): Extrahuje text z obrázků nebo skenovaných dokumentů. Když je spárováno s VLM, výsledky OCR jsou vylepšeny, protože modely rozumí jak vizuální struktuře, tak textovému významu.
-
Modely Vision-Language (VLM): VLM revolucionalizují extrakci tabulek integrací vizuálních a jazykových datových procesů. Vynikají v:
- Rozpoznávání složitých rozvržení tabulek a nepravidelných hranic.
- Interpretaci vztahů mezi řádky, sloupci a hlavičkami.
- Zpracování tabulek v různých formátech, včetně obrázků a PDF, s vícejazyčnou podporou. VLM umožňují hlubší kontextové porozumění, což zajišťuje, že extrahovaná data si zachovávají svůj původní význam a strukturu.
-
Zpracování Přirozeného Jazyka (NLP): Analyzuje a organizuje extrahovaná data, zajišťuje sémantickou koherenci. VLM dále vylepšují NLP poskytováním kontextových nápověd z vizuálních vzorů.
-
Algoritmy Hlubokého Učení: Školí modely k detekci hranic tabulek, hierarchií buněk a vzorců v nestrukturovaných dokumentech. Když jsou obohaceny o VLM, tyto algoritmy dosahují větší přesnosti a přizpůsobivosti.
Důraz na VLM posunul AI extrakci tabulek z úkolu jednoduchého získávání dat na úkol kontextualizovaného porozumění, což ji činí neocenitelnou pro průmyslová odvětví, kde jsou přesnost a nuance zásadní.
Případové Studie AI Extrakce Tabulek
AI poháněná extrakce tabulek transformuje průmyslová odvětví automatizací procesu extrakce a organizace tabulkových dat z různých formátů dokumentů. Níže jsou uvedeny některé pozoruhodné případy použití, kde inteligentní extrakce tabulek prokázala svou neocenitelnost:
-
Finance: Extrakce strukturovaných dat z finančních výkazů, faktur a zpráv je často pracný úkol. AI usnadňuje kopírování tabulky z PDF do Excelu, což umožňuje rychlejší vyrovnání, analýzu a reportování.
-
Zdravotnictví: Organizace výsledků klinických zkoušek, pacientských záznamů nebo dat lékařského výzkumu je zjednodušená. Například poskytovatelé zdravotní péče mohou snadno kopírovat tabulku z PDF do Excelu, což zajišťuje, že data jsou připravena k integraci do systémů elektronických zdravotních záznamů (EHR).
-
Právo: Analýza smluv a extrakce strukturovaných klauzulí z vnořených tabulek pomáhá právním týmům pracovat efektivněji. AI modely usnadňují kopírování tabulky z PDF do Excelu, což šetří čas na kontroly souladu a právní výzkum.
-
Výzkum a Akademie: Výzkumníci mohou rychle extrahovat data z vědeckých článků, což zjednodušuje úkol převodu klíčových metrik pomocí nástrojů pro kopírování tabulky z PDF do Excelu, což činí datové sady připravené pro statistickou analýzu.
Schopnost AI extrakce tabulek přesně zpracovávat různé formáty dokumentů revolucionalizuje pracovní toky, což usnadňuje kopírování, organizaci a analýzu tabulkových dat v Excelových listech.
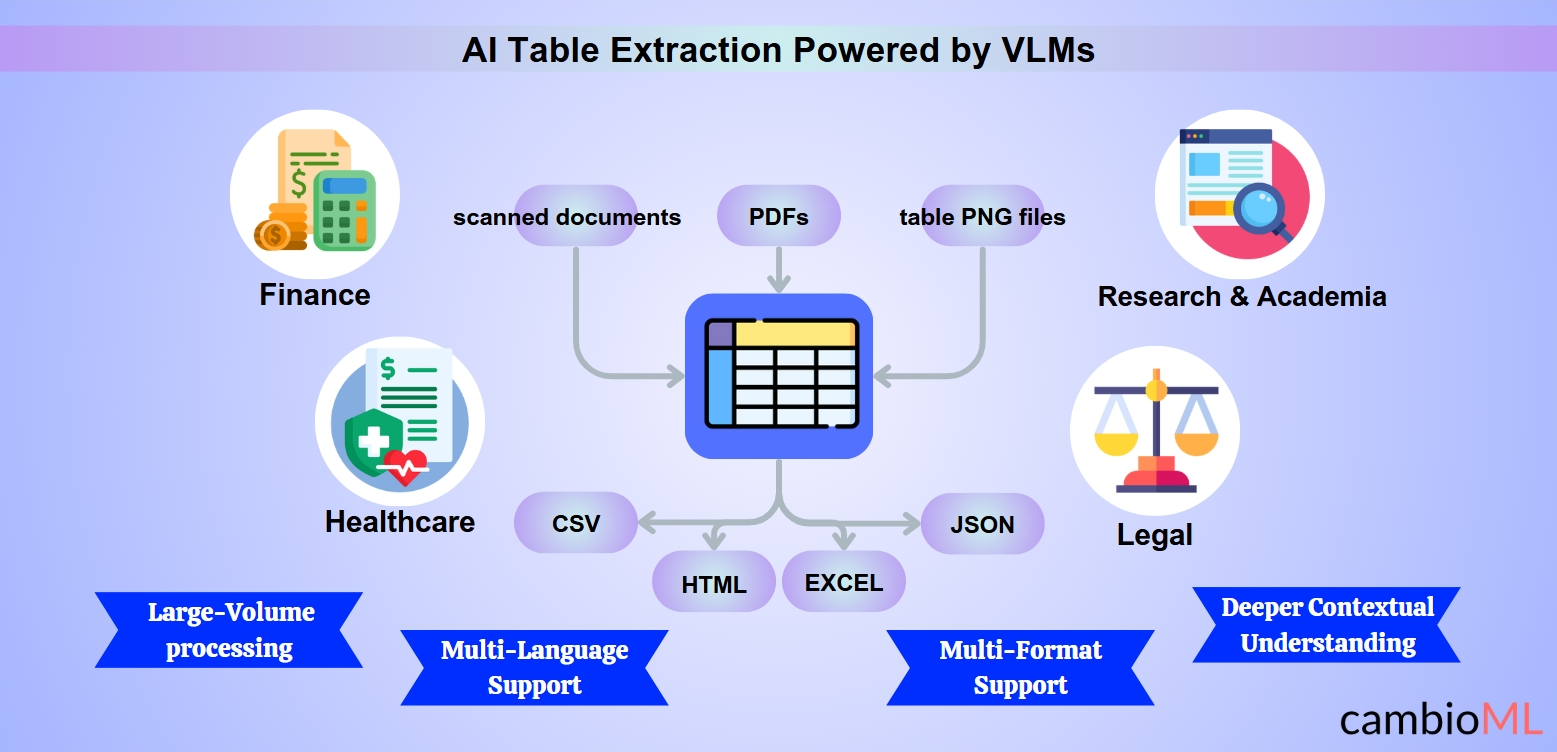
Výhody Inteligentní Extrakce Tabulek
AI extrakce tabulek nabízí řadu výhod, zejména v zlepšení efektivity, přesnosti a škálovatelnosti. Využitím pokročilých technologií, včetně modelů Vision-Language (VLM), mohou firmy překonat tradiční výzvy v extrakci tabulek:
-
Automatizace a Úspora Času: Opakující se úkoly, jako je ruční kopírování tabulek z PDF do Excelu, jsou eliminovány, což umožňuje zaměstnancům soustředit se na činnosti s vyšší hodnotou.
-
Zlepšená Přesnost: AI modely významně snižují chyby, které jsou běžné, když uživatelé ručně kopírují tabulku z PDF do Excelu nebo se spoléhají na základní nástroje. Tyto modely zajišťují, že data si zachovávají svou strukturu a význam.
-
Škálovatelnost pro Zpracování Velkých Objeme: AI nástroje jsou navrženy tak, aby zvládaly hromadnou extrakci dat. Ať už se jedná o finanční záznamy, výzkumné dokumenty nebo soubory pro dodržování předpisů, zjednodušují proces extrakce a organizace dat v Excelu.
-
Podpora Více Formátů a Jazyků: Inteligentní systémy mohou zpracovávat dokumenty v různých formátech a jazycích, což umožňuje bezproblémovou extrakci a kopírování tabulky z PDF do Excelu i v komplexních, vícejazyčných kontextech.
AI extrakce tabulek nejen zjednodušuje pracovní toky, ale také zajišťuje kontextovou integritu dat, což mění způsob, jakým průmyslová odvětví zacházejí s tabulkovými informacemi. Tato efektivita je v dnešním datově orientovaném světě klíčová, kde rychlé a přesné zpracování tabulkových dat představuje konkurenční výhodu.
Řešení Výzev Více Formátů a Více Jazyků
Moderní AI řešení excelují v řešení variability formátů a jazyků, což zajišťuje konzistentní přesnost a efektivitu napříč různými datovými sadami:
-
Schopnosti Více Formátů: Nástroje poháněné AI mohou bez námahy zpracovávat PDF, skenované dokumenty a obrázkové soubory jako tabulky PNG. Tato univerzálnost je obzvlášť kritická, když uživatelé potřebují extrahovat tabulku z PDF nebo převést obrázek na tabulku pro analýzu a reportování.
-
Podpora Více Jazyků: AI modely jsou školeny na vícejazyčných datových sadách, což jim umožňuje zpracovávat dokumenty v různých jazycích. Tato funkce je neocenitelná pro globální průmyslová odvětví, která se zabývají mezinárodní dokumentací.
-
Zachování Vztahů Dat: Ať už se jedná o zpracování obrázku na tabulku nebo extrakci složité struktury z PDF, AI systémy zajišťují, že hlavičky, řádky a sloupce jsou zachovány, což udržuje integritu dat.
Řešením těchto výzev se AI řešení etablovala jako nepostradatelné nástroje pro organizace, které se zabývají velkými, vícejazyčnými a vícerozměrnými dokumenty.
Budoucnost AI v Extrakci Tabulek
Budoucnost AI extrakce tabulek je světlá, s pokroky, které mají dále zlepšit její schopnosti:
-
Vylepšené Modely Vision-Language (VLM): Nové technologie VLM poskytnou ještě sofistikovanější způsoby, jak extrahovat tabulku z PDF a převádět složité formáty tabulek PNG na strukturovaná data. Tyto modely překlenou mezeru mezi vizuálními prvky a textovým porozuměním.
-
Integrace s Generativní AI: Integrací generativní AI mohou budoucí řešení nejen extrahovat tabulku z PDF nebo obrázků, ale také analyzovat extrahovaná data pro poznatky, shrnutí a doporučení.
-
Automatizace od Začátku do Konce: Nástroje poháněné AI zjednoduší pracovní toky automatickým převodem souborů, například transformací obrázku na tabulku, kategorizací dat a jejich přímým zasíláním do analytických pipeline.
-
Širší Přístupnost: AI systémy se stanou uživatelsky přívětivějšími a dostupnějšími, což umožní i netechnickým uživatelům snadno zpracovávat soubory tabulek PNG nebo extrahovat data bez námahy.
AI extrakce tabulek je připravena redefinovat zpracování dokumentů, což činí extrakci dat rychlejší, chytřejší a přizpůsobivější k vyvíjejícím se potřebám průmyslu. Firmy, které tyto řešení přijmou, získají konkurenční výhodu v efektivním řízení a využívání svých dat.
AnyParser: Revoluční Nástroj pro Zpracování Dokumentů a Extrakci Tabulek
AnyParser je na čele inteligentního zpracování dokumentů, nabízí firmám efektivní a spolehlivý způsob, jak extrahovat data i z těch nejkomplexnějších dokumentů. Jeho pokročilé schopnosti jsou obzvlášť patrné, pokud jde o extrakci tabulek, což zajišťuje přesné a škálovatelné zachycení dat pro různá průmyslová odvětví.
Klíčové Výhody AnyParser pro Extrakci Tabulek
-
Komplexní Podpora Formátů: Ať už se jedná o PDF, obrázky nebo jiné typy souborů, AnyParser zjednodušuje zachycení dat přesným extrahováním tabulkových informací bez ohledu na formát.
-
Vysoká Přesnost a Kontextové Porozumění: Na rozdíl od tradičních nástrojů, AnyParser zachovává strukturu, vztahy a kontext tabulkových dat, poskytující výsledky připravené k analýze a integraci.
-
Efektivita Poháněná AI: Díky modelům Vision-Language (VLM) exceluje AnyParser v prostředích s více jazyky a formáty, což zajišťuje bezproblémové zachycení dat ve velkém měřítku.
-
Přizpůsobitelné Pracovní Postupy: Platforma se přizpůsobuje vašim jedinečným potřebám, ať už extrahujete finanční tabulky, zdravotnické záznamy nebo výzkumná data.
S AnyParser mohou firmy optimalizovat své procesy, minimalizovat chyby a šetřit čas automatizací složitého úkolu extrakce tabulek pro strukturované zachycení dat.
Závěr
AI poháněná extrakce tabulek redefinovala způsob, jakým firmy zpracovávají a využívají strukturovaná data. Ať už je úkolem extrakce tabulek z PDF, zpracování obrázků nebo dosažení přesného zachycení dat, nástroje jako AnyParser usnadňují transformaci nestrukturovaných dokumentů na akční poznatky. AnyParser je vaše důvěryhodné řešení pro zjednodušení zpracování dokumentů, poskytující bezkonkurenční přesnost a efektivitu. Díky své schopnosti zvládat různé formáty a kontexty umožňuje AnyParser organizacím automatizovat své pracovní toky a odemknout plný potenciál svých dat.
Výzva k Akci
Proč čekat na to, abyste zažili další úroveň zpracování dokumentů? Odemkněte plný potenciál AnyParser vyzkoušením jeho funkcí v praktickém prostředí!
Klikněte na odkaz níže a vstupte do Sandboxu, kde můžete prozkoumat, jak to zjednodušuje:
- Přesné zachycení dat z PDF a obrázků.
- Bezproblémovou extrakci tabulek pro integraci do analytických nástrojů.
- Spolehlivý výkon napříč komplexními a velkými datovými sadami.
Zažijte AnyParser v Sandboxu nyní
Nenechte si ujít příležitost vidět, jak může AnyParser revolucionalizovat vaše pracovní toky. Otestujte to ještě dnes a objevte, jak snadné může být zpracování dokumentů a extrakce tabulek!