V oblasti správy dat zahrnuje parsing převod obsahu—například textu, obrázků, tabulek a metadat—do použitelného formátu (např. prostý text, strukturovaná data nebo obrázky), který může být dále zpracován nebo analyzován. To je obzvlášť patrné v oblasti PDF parsování, vstupte do světa parsování, což je zásadní proces, který přetváří surové informace na strukturovaná, použitelná data. Tento komplexní průvodce se zabývá složitostmi PDF parsování, objasňuje jeho definici, spektrum dat, která může extrahovat, překážky, kterým čelí, jeho mnohostranné aplikace a bohatství metod, které jsou k dispozici pro využití jeho plného potenciálu. Prozkoumáte různé metody parsování, se zvláštním zaměřením na PDF parsování a na to, jak se nástroje jako AnyParser odlišují od ostatních.
Pochopení PDF parseru: Co je parsing?
Co je parsing: pečlivý proces zachycování dat
V jádru se PDF parsování týká procesu extrakce a interpretace dat z PDF (Portable Document Format) souborů. Protože jsou PDF navrženy především pro zobrazení, nikoli pro strukturované ukládání dat, zahrnuje parsing převod obsahu—například textu, obrázků, tabulek a metadat—do použitelného formátu (např. prostý text, strukturovaná data nebo obrázky), který může být dále zpracován nebo analyzován. Parsování zahrnuje analýzu na vysoké úrovni, aby se určila a získala konkrétní prvky v PDF, přičemž se rozšiřuje nad rámec pouhého textu a obrázků a zahrnuje písma, rozvržení, tabulky a metadata. Tento proces není pouze technikálií, ale nutností v odvětvích, jako je finance, právo, logistika a zdravotnictví, kde je přepracování informací zásadní.
Data, která lze parsovat z PDF
Data, která lze extrahovat z PDF, jsou různorodá a rozsáhlá, včetně:
-
Textových odstavců: Sekvence slov a znaků.
-
Jednotlivých datových polí: Individuální prvky, jako jsou data, sledovací čísla a jména.
-
Tabulkových dat: Informace organizované do tabulek a seznamů.
-
Obrázků: Grafický obsah vložený do PDF.
-
Pokročilých prvků: Záhlaví, objekty, křížové odkazy, trailer a metadata, které vyžadují sofistikovanější nástroje pro parsování.
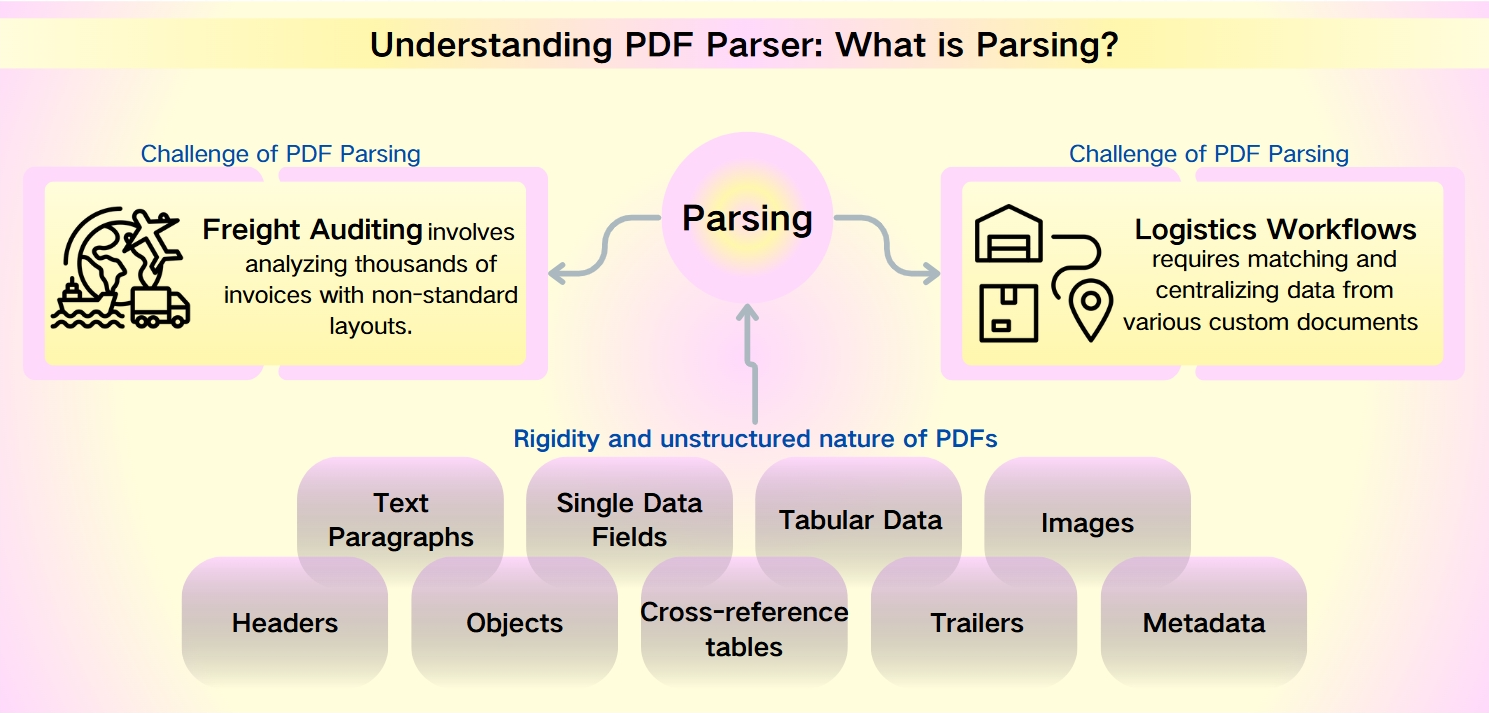
Výzvy PDF parsování: neestrukturovaná povaha PDF metadat
Navzdory robustnosti PDF—charakterizované jejich bezpečností, kompatibilitou s zařízeními a kompaktními velikostmi souborů—představuje extrakce dat z nich značnou výzvu. Rigidity a neestrukturovaná povaha PDF brání rychlé analýze a získávání informací. To je obzvlášť patrné v situacích, jako je audit nákladů a logistické pracovní toky, kde nestandardní rozvržení a objemná datová sada zvyšují složitost.
Audit nákladů zahrnuje analýzu tisíců faktur s nestandardními rozvrženími. Logistické pracovní toky vyžadují shodování a centralizaci dat z různých vlastních dokumentů, jako jsou balicí seznamy, obchodní faktury a nákladní listy.
Význam parsování
Parsování hraje zásadní roli v různých oblastech, od webového vývoje po zachycování dat. Umožňuje firmám extrahovat cenné poznatky z neestrukturovaných zdrojů dat, jako jsou PDF dokumenty, HTML soubory a XML data. Parsování usnadňuje:
-
Zlepšení rozhodování prostřednictvím datově řízených poznatků.
-
Vylepšení přesnosti a konzistence dat.
-
Zjednodušení zpracování a analýzy dat.
-
Efektivní získávání a ukládání informací.
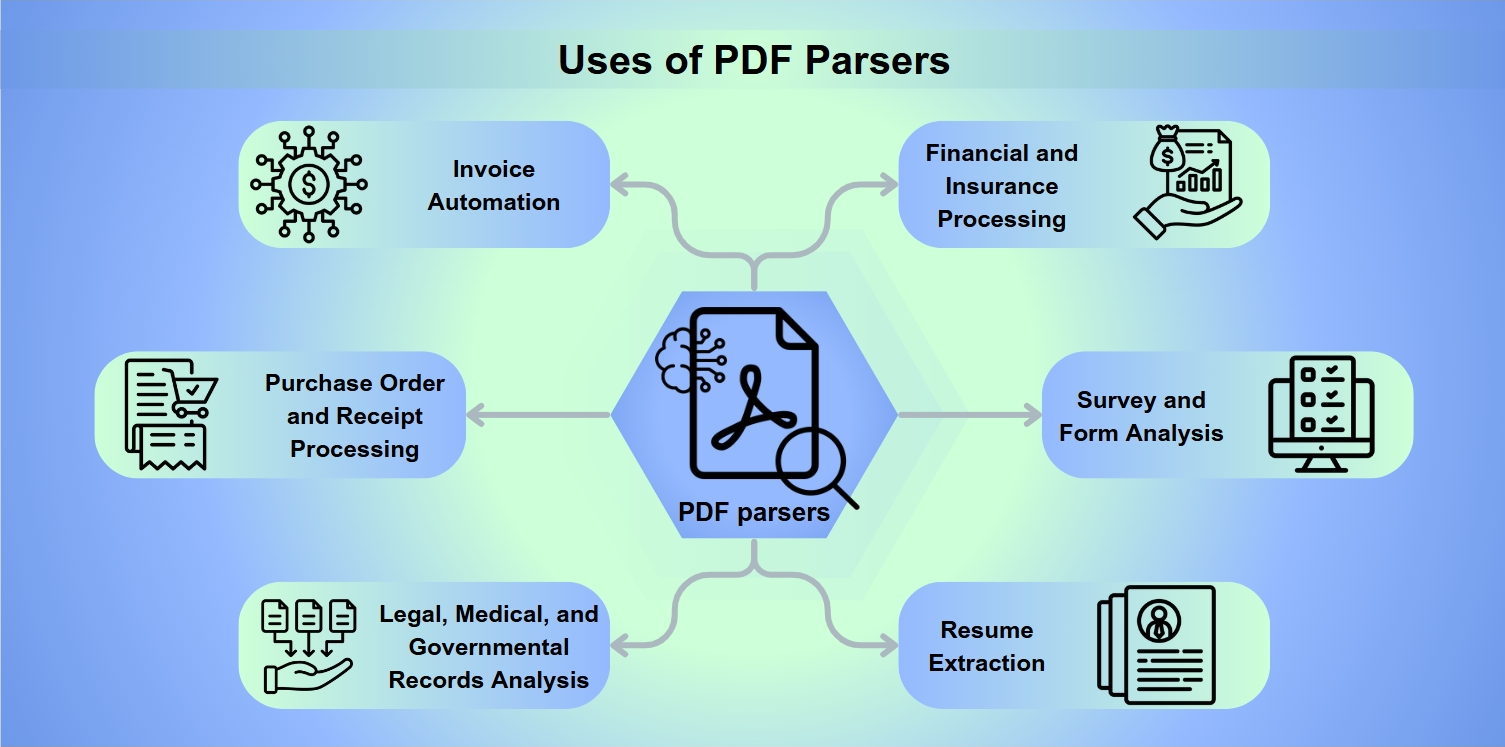
Použití PDF parserů
PDF parsery jsou nezbytné nástroje v široké škále aplikací, včetně:
-
Automatizace faktur: Zjednodušení zpracování a platby faktur.
-
Zpracování objednávek a příjmových dokladů: Usnadnění vrácení a náhrad.
-
Analýza právních, lékařských a vládních záznamů: Umožnění hloubkové extrakce dat pro analýzu.
-
Finanční a pojišťovací zpracování: Hodnocení rizika a analýza rozvah.
-
Analýza průzkumů a formulářů: Shromažďování a interpretace odpovědí z formulářů.
-
Extrakce životopisů: Pomoc personalistům při výběru kandidátů.
Srovnání různých metod parsování
Metody parsování dat se v průběhu času výrazně vyvinuly. Tradiční přístupy k zachycování dat často spoléhají na regulární výrazy (regex) k extrakci konkrétních vzorů z textu. Ačkoli jsou mocné, regex může být složitý a obtížně udržovatelný pro složité úkoly parsování. Další běžnou technikou je manipulace s řetězci, která zahrnuje rozdělení a zpracování textu na základě oddělovačů nebo konkrétních znaků. Tyto metody, ačkoli stále užitečné v určitých scénářích, mohou mít potíže s neestrukturovanými nebo nekonzistentními formáty dat.
Krajina PDF parsování je obsluhována různými metodami, z nichž každá má své jedinečné výhody a nevýhody:
-
Online PDF převodníky/parsery: Jako Zamzar a Smallpdf nabízejí pohodlí a rychlost, ale jsou omezeny ve funkčnosti a potenciálně nebezpečné.
-
Adobe Acrobat: Zachovává strukturu a formátování, ale může vyžadovat manuální úpravy po převodu.
-
Kopírování a vkládání: Poskytuje úplnou kontrolu, ale je pracné a náchylné k chybám.
-
Automatizované platformy: Moderní technologie parsování, jako je AnyParser, využívají strojové učení a zpracování přirozeného jazyka (NLP) k zvládnutí složitějších datových struktur.
Tyto přístupy řízené AI dokážou porozumět kontextu a sémantice, což je činí zvlášť efektivními pro parsování neestrukturovaného textu nebo dokumentů s různými formáty. Některé pokročilé parsery využívají modely hlubokého učení k identifikaci a extrakci relevantních informací s vysokou přesností, i z dříve neviděných rozvržení dokumentů.
Jak provádět PDF parsování: Nejlepší bezplatný PDF parser pro extrakci PDF metadat
Pochopení PDF metadat
PDF metadata obsahují zásadní informace o dokumentu, včetně jeho názvu, autora, data vytvoření a klíčových slov. Efektivní extrakce těchto metadat je nezbytná pro organizaci, vyhledávání a správu velkých sbírek PDF souborů. Robustní PDF parser může tento proces zjednodušit, šetřit čas a zlepšovat produktivitu pracovního toku.
Klíčové vlastnosti nejlepších PDF parserů
Nejlepší bezplatné PDF parsery nabízejí kombinaci přesnosti, rychlosti a všestrannosti. Měly by být schopny zpracovávat různé formáty PDF, včetně skenovaných dokumentů a těch se složitými rozvrženími. Hledejte parsery, které dokážou extrahovat nejen základní metadata, ale také vlastní pole a skryté informace. Kromě toho často nabízejí možnosti pro extrakci dat z PDF pro hromadné zpracování a integraci s jinými softwarovými systémy.
Vlastnosti AnyParser
AnyParser, vyvinutý společností CambioML, je zvlášť pozoruhodný díky své přesnosti, ochraně soukromí a konfigurovatelnosti. Schopnost AnyParseru zpracovávat více formátů souborů, jeho uživatelsky přívětivé rozhraní a škálovatelnost z něj činí vynikající volbu pro firmy všech velikostí. Navíc jeho API umožňuje bezproblémovou integraci do stávajících pracovních toků, což zvyšuje celkovou efektivitu správy dokumentů. Zde jsou některé z klíčových funkcí, které činí AnyParser vynikající volbou pro PDF parsování:
-
Přesnost: AnyParser je navržen tak, aby přesně extrahoval text, čísla a symboly při zachování původního rozvržení a formátu. Využívá pokročilé jazykové modely k vylepšení porozumění dokumentu a extrakce informací, s až 2x vyšší přesností ve srovnání s tradičními modely OCR.
-
Ochrana soukromí: Podporuje jak on-prem, tak cloudové parsování dat, čímž zajišťuje, že citlivé informace zůstávají soukromé a zabezpečené.
-
Konfigurovatelnost: Uživatelé si mohou přizpůsobit pravidla extrakce a výstupní formáty podle svých specifických potřeb.
-
Podpora více zdrojů: AnyParser podporuje různé typy dokumentů, včetně PDF, obrázků a grafů.
-
Strukturovaný výstup: Extrahované informace mohou být převedeny do strukturovaných formátů, jako jsou Markdown, Excel nebo JSON, což usnadňuje další zpracování a analýzu.
-
Možnosti nasazení v cloudu: AnyParser SDK může být nasazen v cloudu, datových centrech nebo soukromě, což nabízí flexibilitu a škálovatelnost.
-
Uživatelsky přívětivé rozhraní: Nástroj nabízí jednoduché API, které umožňuje provádět složité úkoly parsování dokumentů s pouhými několika řádky kódu.
-
Vysoký výkon: Optimalizované algoritmy zajišťují rychlé zpracování velkého počtu dokumentů, 5x rychleji než generalizované LLM, jako je GPT4o.
-
Podpora komunity: Jako open-source projekt těží AnyParser z aktivní komunity a vítá příspěvky.
-
Bezplatná kvóta pro používání: AnyParser nabízí bezplatnou kvótu pro používání s každým účtem, což uživatelům umožňuje otestovat schopnosti nástroje před přechodem na placený plán.
-
Zpětná vazba zákazníků: Uživatelé chválí AnyParser za jeho vysokou přesnost, ochranu soukromí a efektivitu při extrakci dat, přičemž případové studie ukazují na významné úspory času a zlepšení kvality dat.
Tyto výhody činí AnyParser cenným nástrojem pro extrakci dat z PDF a parsování dokumentů, zejména pro podnikové uživatele, kteří vyžadují vysokou přesnost a zabezpečení. S pokračujícími technologickými pokroky a aktivním zapojením komunity je AnyParser připraven hrát stále důležitější roli v oblasti parsování dokumentů a extrakce informací.
Technické vysvětlení PDF parserů
PDF parsování sdílí konceptuální základ s web scrapingem, přesto mu chybí strukturovaná hierarchie HTML. Zatímco webové dokumenty jsou parsovány prostřednictvím přístupných HTML tagů, PDF představují plochou řadu znaků a pixelů, což vyžaduje sofistikovanější algoritmy a knihovny pro extrakci dat.
PDF parser vs Python PDF parser: Klíčové rozdíly
PDF parser je často samostatný nástroj jako pdf data extractor nebo knihovna navržená speciálně pro extrakci dat z PDF souborů. Tyto parsery obvykle nabízejí uživatelsky přívětivá rozhraní a vyžadují minimální znalosti programování. Na druhé straně Python PDF parsers jsou moduly nebo knihovny, které se integrují do Python skriptů, což poskytuje větší flexibilitu, ale vyžaduje programátorské dovednosti.
Vývojáři mohou jemně doladit proces parsování, implementovat pokročilou analýzu textu a bezproblémově integrovat extrakci dat z PDF do širších Python aplikací. PDF parsers, i když jsou omezenější v přizpůsobení než python PDF parser, často poskytují předem vytvořené funkce pro běžné případy použití, což je činí ideálními pro uživatele, kteří potřebují rychlé výsledky bez rozsáhlého programování.
Výhody AnyParser s VLM pro parsování dat
-
Vysoká přesnost: VLM AnyParseru zajišťují, že extrakce dat udržuje vysokou věrnost, i s komplexními rozvrženími dokumentů.
-
Rychlost: Vyniká v rychlosti převodu, čímž zvyšuje produktivitu snížením času potřebného k zpracování dokumentů.
-
Uživatelsky přívětivé: AnyParser nabízí jednoduché rozhraní, což jej činí přístupným pro uživatele všech úrovní.
-
Všestrannost: Kromě PDF slouží AnyParser jako mocný převodník obrázků do Excelu, podporující různé typy dokumentů.
Závěr
PDF parsování je víc než jen technický proces; je to brána k transformaci způsobu, jakým firmy zacházejí s daty. Navzdory výzvám učinil vývoj softwarových řešení tento proces přístupnějším než kdy jindy. Ať už se zabýváte zpracováním faktur nebo komplexní analýzou dat, výběr správného PDF parseru je zásadní. Jde o nalezení nástroje, který nabízí dokonalou rovnováhu mezi přesností, bezpečností a efektivitou, aby podpořil vaše iniciativy řízené daty.
Začněte svou bezplatnou zkušební verzi ještě dnes
Připraveni revolucionalizovat své zpracování dokumentů? Vyzkoušejte AnyParser ZDARMA bez nutnosti zadávat číslo kreditní karty na https://www.cambioml.com/sandbox. Bezplatná zkušební verze umožňuje zpracovat až 10 stránek na dokument s maximální velikostí souboru 10 MB. Zažijte na vlastní kůži, jak může PDF parser AnyParser transformovat váš přístup k neestrukturovaným datům a extrakci dokumentů. Nenechte si ujít tuto příležitost zlepšit své schopnosti analýzy dat a zjednodušit svůj pracovní tok s nejmodernější technologií AI.