Převod složitých PDF do Markdownu může být náročný. Existuje mnoho open-source knihoven, které umožňují extrakci textu z PDF, ale pokud jde o PDF obsahující složité prvky jako tabulky a grafy, výsledky často zaostávají. Populární velké jazykové modely jako GPT nebo Claude tyto úkoly zvládají, ale bývají pomalé a někdy produkují nepřesné výstupy. Tradiční nástroje OCR, i když jsou efektivní pro jednodušší dokumenty, často bojují s udržením přesné struktury a sémantického významu původního obsahu. Na druhé straně modely jazykového vidění někdy halucinuji, což vede k chybným výsledkům analýzy. Tento blog vysvětlí, co znamená analýza a podrobně popíše výsledky srovnávací analýzy několika modelů pomocí různých metrik.
Co znamená analýza?
V kontextu analýzy PDF se "analýza" vztahuje na proces extrakce specifických dat z PDF souboru pomocí specializovaného softwaru známého jako PDF parser. PDF parser analyzuje obsah PDF dokumentu a identifikuje prvky jako text, obrázky, písma, rozvržení a dokonce i metadata. Extrahovaná data mohou být následně organizována a exportována do různých formátů jako XML, JSON nebo Excel/CSV, které mohou být použity pro různé účely, jako je analýza dat, vedení záznamů nebo automatizace pracovních postupů.
Pochopení toho, co znamená analýza, je zásadní pro hodnocení účinnosti řešení pro analýzu, zejména při porovnávání různých nástrojů pro převod PDF do Markdownu, protože PDF parser zahrnuje více než jen jednoduchou extrakci textu—vyžaduje rozpoznání a udržení sémantické struktury dokumentu.
Jak měříme kvalitu těchto řešení pro analýzu?
Definovali jsme sérii metrik na úrovni slov pro posouzení výkonu různých modelů, zaměřující se na klíčové faktory jako:
-
Přesnost, Recall a F-Míra: Hodnocení kvality a úplnosti analýzy.
-
BLEU Skóre a ANLS: Užitečné pro hodnocení jazykové a struktury rozvržení.
-
Edit Distance, Jenson-Shannon Divergence a Jaccard Distance: Metriky specifické pro oblast OCR, obzvlášť užitečné pro pochopení přesnosti reprodukce obsahu.
Náš model jazykového vidění, AnyParser, vykazuje výjimečný výkon, kombinuje rychlost a přesnost, zejména na složitých rozvrženích s tabulkami a sémantickými prvky. AnyParser překonává ostatní řešení, nabízí 20x zlepšení rychlosti oproti modelům jako GPT/Claude při dosahování vyšší přesnosti.
Rozsáhlé srovnání výsledků proti předním modelům pro analýzu
Statistický objekt
Abychom skutečně ukázali schopnosti AnyParser, provedli jsme rozsáhlé srovnání proti předním modelům pro analýzu v oboru a známým velkým jazykovým modelům (LLMs). Naše hodnocení zahrnovalo:
1. Velké jazykové modely
- AnyParser
- OpenAI's GPT-4o
- Google's Gemini 1.5 Pro
- Anthropic's Claude 3.5 Sonnet
2. Služby založené na OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Prezentace a analýza výsledků
Experiment 1
Nejprve provádíme sérii přísných srovnání výkonu různých modelů AI pro dokumenty na více než 5 metrikách níže: BLEU, přesnost a recall, F-míra a ANLS. Matematickou definici těchto metrik naleznete v dodatku.
Modely, které byly porovnány: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl a Azure-DocAl.
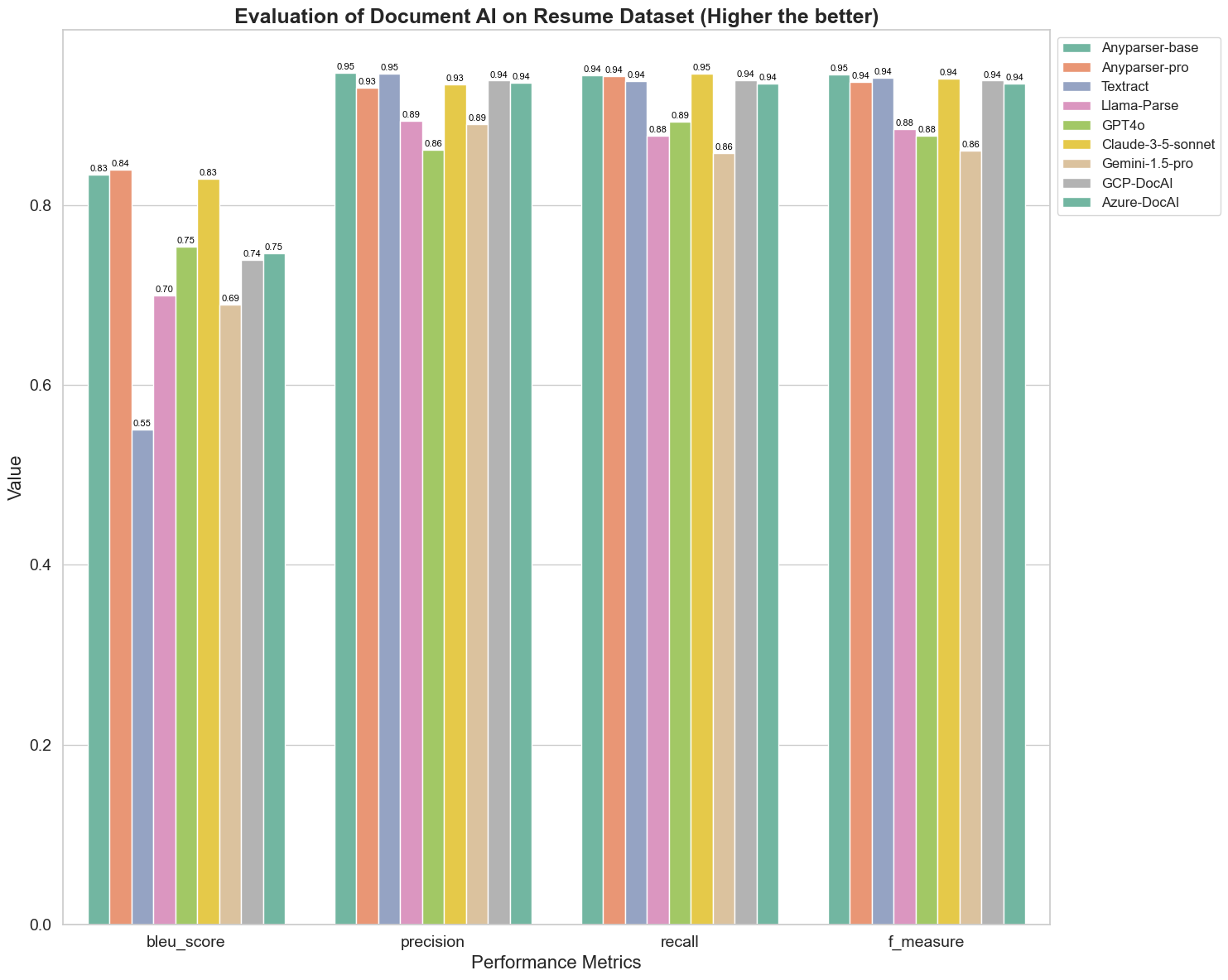
BLEU se používá jako hodnocení kvality dvojjazyčného tlumočení k testování kvality modelů při zpracování výroků. Porovnáním výsledků těchto modelů analýzy podle metody hodnocení BLEU zjišťujeme, že: skóre AnyParser-base a AnyParser-pro jsou výrazně vyšší než skóre ostatních modelů, Amazon Textract má nejnižší skóre a výsledky ostatních modelů se nacházejí na střední, relativně průměrné úrovni.
Přesnost rozpoznávání je obvykle reprezentována přesností a recall, kde přesnost představuje procento skutečně správných výsledků mezi výsledky posouzenými jako správné modelem a recall představuje procento skutečně správně posouzených výsledků modelem mezi všemi skutečně správnými výsledky. Porovnáním přesnosti a recall těchto modelů analýzy zjišťujeme, že: kromě Llama-Parse, GPT4o a Gemini-1.5-pro, všechny ostatní modely jsou na vysoké úrovni. Mezi nimi se AnyParser a Amazon Textract vyznačují vyšší přesností, a AnyParser-base a AnyParser-pro se vyznačují vyšším recall. Vyšší skóre modelu na přesnosti naznačuje, že model produkuje více správných informací v produkčních výsledcích, a vyšší skóre na recall naznačuje, že model je schopnější získat správné informace ze vzorku. Výsledky ukazují, že AnyParser má jasnou výhodu v oblasti přesnosti rozpoznávání pro extrakci textu z PDF.
F-Míra je komplexní hodnotící index přesnosti a recall na těchto dvou ukazatelích. Porovnáním skóre těchto modelů analýzy podle F-Míry můžeme intuitivně vidět, že pět modelů, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI a Azure-DocAI, mají lepší sílu v oblasti přesnosti rozpoznávání ve srovnání s ostatními modely. Můžeme intuitivně vidět, že pět modelů má větší sílu v přesnosti rozpoznávání než ostatní modely, a AnyParser má nejvyšší skóre podle F-Míry, což dále ilustruje zřejmou výhodu AnyParser v přesnosti rozpoznávání pro extrakci textu z PDF.
ANLS, jako běžně používaný hodnotící index při měření přesnosti a podobnosti mezi původním textem a cílovým textem na úrovni znaků, je také velmi informativní pro měření úrovně analýzy modelů. Vyšší skóre AnyParser-base, AnyParser-pro a Azure-DocAI odráží vyšší úroveň analýzy těchto modelů ve srovnání s ostatními modely.
Celkově AnyParser-base a AnyParser-pro překonávají ostatní modely.
Experiment 2
Také porovnáváme výkon různých modelů AI pro dokumenty na třech různých metrikách: Edit Distance, Jensen-Shannon Divergence a Jaccard Distance. Metriky se používají k měření podobnosti mezi výstupem modelů a referenčním dokumentem. Nižší hodnoty naznačují lepší výkon.
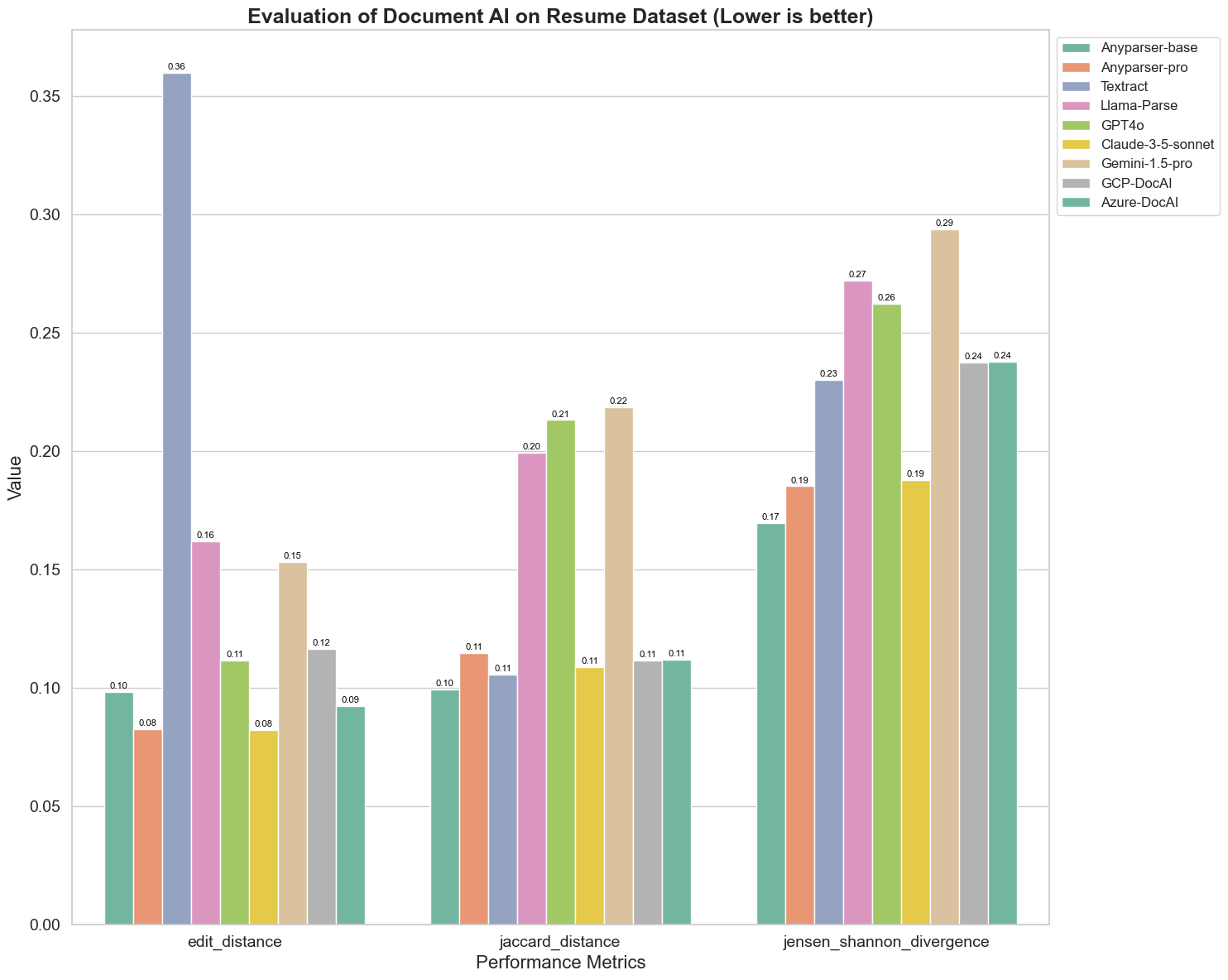
Zde jsou některé klíčové poznatky z grafu:
-
Edit Distance: Modely AnyParser-base a AnyParser-pro vykazují nejlepší výkon s nejnižší edit distance, což naznačuje, že jejich výstupy jsou nejblíže referenčnímu dokumentu.
-
Jensen-Shannon Divergence: Modely AnyParser-base a AnyParser-pro mají nejnižší divergenci, což naznačuje, že jejich výstupy jsou nejpodobnější referenčnímu dokumentu z hlediska rozložení slov.
-
Jaccard Distance: Kromě Llama-parse, GPT4O, Gemini-1.5, všechny ostatní modely vykazují slušný výkon s nejnižší Jaccard distance, což naznačuje, že jejich výstupy mají nejvyšší překryv s referenčním dokumentem z hlediska použité sady slov.
Závěr
Celkově naše přísné testování naznačuje, že AnyParser-base a AnyParser-pro obecně vykazují dobrý výkon napříč různými metrikami, což naznačuje jejich potenciál pro přesné zpracování dokumentů. Z grafů vidíme, že tradiční modely OCR, jako je známý Amazon Textract, dosahují mnohem nižších skóre než modely jazykového vidění. Nicméně výkon různých modelů se liší v závislosti na použité metrice, což zdůrazňuje důležitost zohlednění více hodnotících kritérií při porovnávání AI modelů.
Představujeme náš open-source hodnotící pipeline
Abychom zjednodušili hodnocení, vytvořili jsme hodnotící pipeline, která poskytuje standardizovanou metodu pro porovnávání modelů analýzy. V našem příkladu demonstrujeme její použití v oblasti HR, kde je běžné zpracování životopisů. Vytvořili jsme různorodý syntetický dataset 128 životopisů, generovaných pomocí párovaných souborů obrázků-Markdown. Pomocí GPT-4 jsme generovali HTML obsah, renderovali ho do obrázků a použili extrahovaný text jako základ pro srovnání.
A tady je ta nejlepší část: tento hodnotící rámec jsme zveřejnili jako open-source na GitHubu! Ať už jste vývojář nebo obchodní uživatel, naše pipeline vám umožňuje hodnotit a porovnávat kvalitu analýzy různých modelů na vašem vlastním datasetu.
Najděte rychlý průvodce v Github repo a zjistěte, jak si různé modely analýzy vedou navzájem. Věříme, že tím, že ukážeme sílu našeho modelu na veřejnosti, můžeme přilákat více uživatelů, kteří chtějí spolehlivé, rychlé a přesné schopnosti analýzy.
Dodatek - Metriky
1. Přesnost
Přesnost měří přesnost analyzovaného obsahu, ukazuje, kolik z vyhledaných prvků bylo správných. V analýze je to podíl správně extrahovaných slov ze všech extrahovaných slov.
Přesnost = Skutečné pozitivní (TP) / (Skutečné pozitivní (TP) + Falešné pozitivní (FP))
- Skutečné pozitivní (TP): Slova správně identifikovaná parserem.
- Falešné pozitivní (FP): Slova nesprávně identifikovaná parserem.
2. Recall
Recall ukazuje úplnost analýzy, nebo kolik relevantních slov z původního dokumentu bylo vyhledáno.
Recall = Skutečné pozitivní (TP) / (Skutečné pozitivní (TP) + Falešné negativní (FN))
- Falešné negativní (FN): Slova v původním dokumentu, která parser přehlédl.
3. F-Míra (F1 Skóre)
F1 Skóre je harmonický průměr přesnosti a recall, vyvažující obě metriky, aby poskytlo celkové měření kvality analýzy.
F1 Skóre = 2 × (Přesnost × Recall) / (Přesnost + Recall)
4. BLEU Skóre (Bilingvní hodnotící podpora)
BLEU skóre měří podobnost mezi analyzovaným obsahem a původním textem, klade zvláštní důraz na pořadí slov. Je obzvlášť užitečné pro hodnocení jazykové a strukturální konzistence v analyzovaných dokumentech, protože penalizuje výstupy, které se liší v sekvenci od původního.
5. ANLS (Průměrná normalizovaná Levenshteinova podobnost)
ANLS kvantifikuje podobnost mezi analyzovaným obsahem a původním, pomocí normalizované edit distance. Vypočítává se průměrováním normalizované Levenshteinovy podobnosti (NLS) pro každý pár slov v analyzovaných a referenčních textech. NLS se vypočítává následovně:
NLS = 1 - (Levenshteinova vzdálenost (LD)(analyzované slovo, původní slovo)) / max(Délka analyzovaného slova, Délka původního slova)
Poté je ANLS průměrem NLS napříč všemi páry slov:
ANLS = (1/N) × Σ(NLS_i) pro i=1 do N
6. Edit Distance
Edit Distance počítá počet operací na úrovni slov (vložením, odstraněním, substitucí), které jsou potřebné k převodu analyzovaného textu na původní.
7. Jensen-Shannon Divergence
Jensen-Shannon Divergence měří podobnost mezi diskrétními pravděpodobnostními rozděleními počtů slov v analyzovaném a původním textu, zdůrazňující rozdíly ve frekvenci slov.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
kde M = (1/2)(P + Q), a KL(P || Q) je Kullback-Leiblerova divergence
8. Jaccard Distance
Jaccard Distance měří nesourodost mezi sadami slov v analyzovaném a původním obsahu, užitečné pro hodnocení překryvu slov.
Jaccard Distance = 1 - |A ∩ B| / |A ∪ B|
kde |A ∩ B| je počet společných prvků mezi A a B,
a |A ∪ B| je celkový počet unikátních prvků v obou sadách.