V mnoha oblastech je extrakce informací z komplexních dat, jako je extrakce tabulek z PDF, klíčová pro rozhodování. Digitální transformace zdůraznila potřebu efektivně extrahovat tabulky z PDF a kopírovat tabulky z PDF do Excelu. Přesto výzvy jako objem dat a složitost formátu brání tradičním metodám extrakce, které často vedou k nepřesnostem a vyžadují manuální zásah pro kopírování tabulek z PDF do Excelu. AnyParser od CambioML nabízí moderní řešení těchto výzev, zjednodušuje proces extrakce dat z PDF s přesností a rychlostí.
Výzvy při kopírování tabulek z PDF do Excelu
Tradiční nástroje pro extrakci PDF nedokážou splnit různé potřeby napříč odvětvími pro extrakci dat z PDF. Jsou neefektivní, náchylné k chybám a mají potíže se složitými rozvrženími a skenovanými dokumenty, což brání jejich využití pro extrakci dat ve velkém měřítku.
Potřeby pro extrakci tabulek z PDF
-
Akademický výzkum: Výzkumníci extrahují data z PDF pro podrobné analýzy.
-
Analýza dat: Firmy kopírují tabulky z PDF do Excelu a extrahují data z reportů pro další zpracování.
-
Správa informací: Organizace převádějí PDF tabulky pro snadnější správu.
-
Právní a finanční sektory: Tyto sektory vyžadují extrakci kritických dat z mnoha PDF.
Existující metody pro extrakci tabulek z PDF
-
Ruční zadávání: Kopírování tabulek z PDF do Excelu je vždy časově náročné a náchylné k chybám.
-
PDF konvertory: Intuitivní, ale mají problémy s kompatibilitou a přizpůsobením.
-
Nástroje pro extrakci: Umožňují selektivní extrakci, ale jsou omezeny na nativní PDF.
-
Extrakcí řízená OCR: Postrádá přesnost u složitých dokumentů a smíšených formátů.
Klíčové výzvy extrakce tabulek z PDF
-
Nepřesnost: Nástroje pomáhající kopírovat tabulky z PDF do Excelu mají potíže se složitými rozvrženími a sloučenými buňkami.
-
Zpracování složitých dokumentů: Obtížnosti při extrakci tabulek z komplikovaných dokumentů. Když je potřeba kopírovat tabulku z PDF do Excelu, zabere to čas na zpracování složitých dokumentů.
-
Manuální úpravy: Častá potřeba manuálních kontrol a oprav.
-
Diverzita ve formátu: Různé formáty PDF vyžadují pracné úpravy formátování. Extrakce dat z PDF nemůže být provedena najednou.
-
Omezení nástrojů: Špatná účinnost u skenovaných dokumentů nebo nízkokvalitních obrázků.
Snadné a rychlé kopírování tabulek z PDF do Excelu: Vyzkoušejte AnyParser
AnyParser nabízí nový přístup k analýze dokumentů, využívající nejnovější pokroky v modelech Vision-Language (VLM) k poskytování přesných, soukromých a konfigurovatelných řešení pro získávání dokumentů. AnyParser je skvělou volbou pro extrakci tabulek z PDF a kopírování tabulek z PDF do Excelu.
Krok za krokem: Jak extrahovat tabulky z PDF pomocí AnyParser
AnyParser, vybavený pokročilými modely Vision Language, je robustní nástroj pro přesnou extrakci tabulek z PDF. Postupujte podle těchto jednoduchých kroků, abyste převedli své PDF tabulky do použitelných formátů, jako je CSV nebo Excel:
-
Nahrajte svůj dokument: Začněte nahráním svého PDF nebo Word dokumentu. Můžete snadno přetáhnout svůj soubor do webového rozhraní AnyParser nebo vložit snímek obrazovky PDF pro rychlé zpracování.
-
Vyberte extrakci tabulky: Pro zaměření na extrakci tabulky vyberte možnost "Pouze tabulka" a klikněte na "Extrahovat". API engine AnyParser přesně detekuje a extrahuje tabulky z vašeho PDF dokumentu.
-
Náhled a ověření: Je důležité zkontrolovat extrahovaná data. Použijte funkci náhledu AnyParser k porovnání počáteční extrakce s originálním dokumentem vedle sebe v uživatelském rozhraní.
-
Stáhněte si svůj CSV: Po extrakci jsou data uložena v souboru .csv. Tento soubor si můžete stáhnout jedním kliknutím nebo jej exportovat přímo do Google Sheets pro další manipulaci.
-
Export pro další použití: Když si budete jisti, že extrakce je přesná, pokračujte k exportu svých dat. Soubor .csv lze importovat do tabulek jako Excel nebo databází pro podrobné analýzy.
Dodržováním tohoto průvodce krok za krokem můžete využít schopnosti AnyParser a modelů Vision Language k transformaci složitých PDF tabulek na strukturované, editovatelné soubory, které se hladce integrují do vašeho pracovního postupu pro zlepšenou analýzu a správu dat.
Zvyšování efektivity s AnyParser pro extrakci tabulek z PDF
AnyParser zjednodušuje extrakci tabulek z PDF, nabízí klíčové výhody, které zvyšují produktivitu a zpracování dat napříč odvětvími:
-
Efektivita a přesnost: Automatizace úkolů extrakce dat umožňuje strategičtější zaměření a minimalizuje chyby, což je nezbytné pro informované rozhodování.
-
Bezpečnost dat: Lokální zpracování dat chrání citlivé informace a vyhovuje standardům ochrany osobních údajů v oboru.
-
Flexibilní přizpůsobení: Uživatelé mohou přizpůsobit parametry extrakce a formáty reportů tak, aby vyhovovaly specifickým analytickým potřebám, což zajišťuje hladkou integraci pracovního postupu.
-
Zvýšené analytické zaměření: Zjednodušením extrakce dat se profesionálové mohou soustředit na analýzu s vyšší hodnotou, což zlepšuje jak kvalitu, tak rychlost.
AnyParser zjednodušuje výzvy extrakce tabulek z PDF, zmocňuje uživatele efektivními a účinnými řešeními pro správu dat.
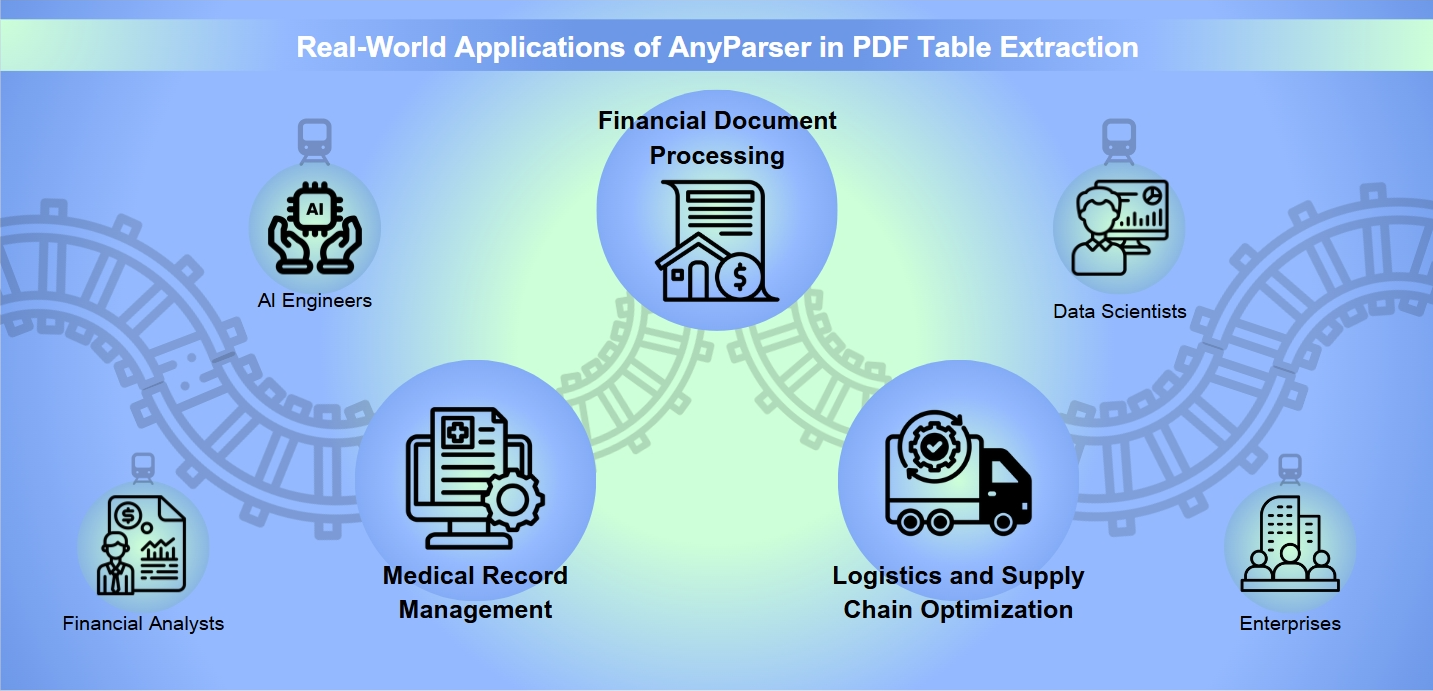
Skutečné aplikace AnyParser při extrakci tabulek z PDF:
Různé profesionální scénáře:
-
Zpracování finančních dokumentů: V oblasti financí AnyParser exceluje v extrakci přesných číselných dat z obrázků nebo PDF tabulek, což zjednodušuje pracovní postup pro finanční analytiky, kteří potřebují přesné informace pro investiční rozhodnutí a finanční reporty.
-
Správa lékařských záznamů: Pro zdravotnické profesionály AnyParser poskytuje spolehlivé řešení pro správu lékařských záznamů. Přesně extrahuje text a informace o rozvržení z PDF, což zajišťuje, že jsou data pacientů organizována a snadno dostupná pro lékařské přezkoumání nebo výzkumné účely.
-
Optimalizace logistiky a dodavatelského řetězce: V logistice AnyParser hraje klíčovou roli při optimalizaci správy dodavatelského řetězce automatizací zpracování a analýzy dokumentů, jako jsou přepravní manifesty a zprávy o inventáři, což vede k efektivnějšímu sledování zásob a plánování tras.
Preferovaná volba pro profesionály jako:
-
AI inženýři: Kteří spoléhají na AnyParser, aby přesně extrahovali text a informace o rozvržení z PDF, což zvyšuje jejich schopnost vyvíjet a trénovat AI modely s kvalitními daty.
-
Finanční analytici: Kteří se spoléhají na nástroj pro extrakci přesných číselných dat z PDF tabulek, což zajišťuje, že jejich finanční analýzy a predikce jsou založeny na přesných a aktuálních informacích.
-
Datoví vědci: Kteří pracují s velkým objemem nestrukturovaných dokumentů a využívají AnyParser k extrakci klíčových informací, což jim umožňuje odhalit poznatky a trendy, které ovlivňují obchodní rozhodnutí.
-
Podniky: Které se snaží automatizovat zpracování a analýzu různých dokumentů, jako jsou smlouvy a zprávy, aby zlepšily provozní efektivitu a rozhodování založené na datech.
Cílením na tyto různé potřeby se AnyParser stává mocným nástrojem, který zvyšuje produktivitu, zajišťuje přesnost dat a usnadňuje digitální transformaci napříč odvětvími.
Technické poznatky o AnyParser: Zvyšování extrakce tabulek z PDF
AnyParser od CambioML využívá modely Vision-Language (VLM) pro pokročilou extrakci tabulek z PDF:
Technické výhody
-
Přesnost založená na VLM: Zajišťuje přesné kopírování tabulek z PDF do Excelu.
-
Modulární design: Umožňuje přizpůsobení pro různé scénáře extrakce dat z PDF.
-
Lokální zpracování: Chrání soukromí dat zpracováním informací lokálně.
-
Vysoký výkon: Rychle zpracovává velké objemy dokumentů pro efektivní extrakci tabulek.
-
API integrace: Nabízí bezproblémové rozhraní pro automatizované pracovní postupy extrakce dat z PDF.
Technická analýza
AnyParser překonává omezení tradiční technologie OCR při zvyšování přesnosti konverze dokumentů tím, že:
-
Interpretuje složité struktury dokumentů: VLM mohou přesně extrahovat data tabulek z PDF, i když mají dokumenty složitá rozvržení.
-
Kontextové porozumění: Poskytují přesnou extrakci dat tím, že chápou kontext, ve kterém se text a tabulky v PDF objevují.
-
Podpora vícero jazyků a formátů: VLM umožňují AnyParser extrahovat tabulky z PDF v několika jazycích a formátech, což z něj činí univerzální nástroj pro globální použití.
-
Snížení šumu: VLM AnyParser efektivně filtrují šum, což zajišťuje vysokou kvalitu extrakce i z nízkokvalitních skenů PDF dokumentů.
Poznámky:
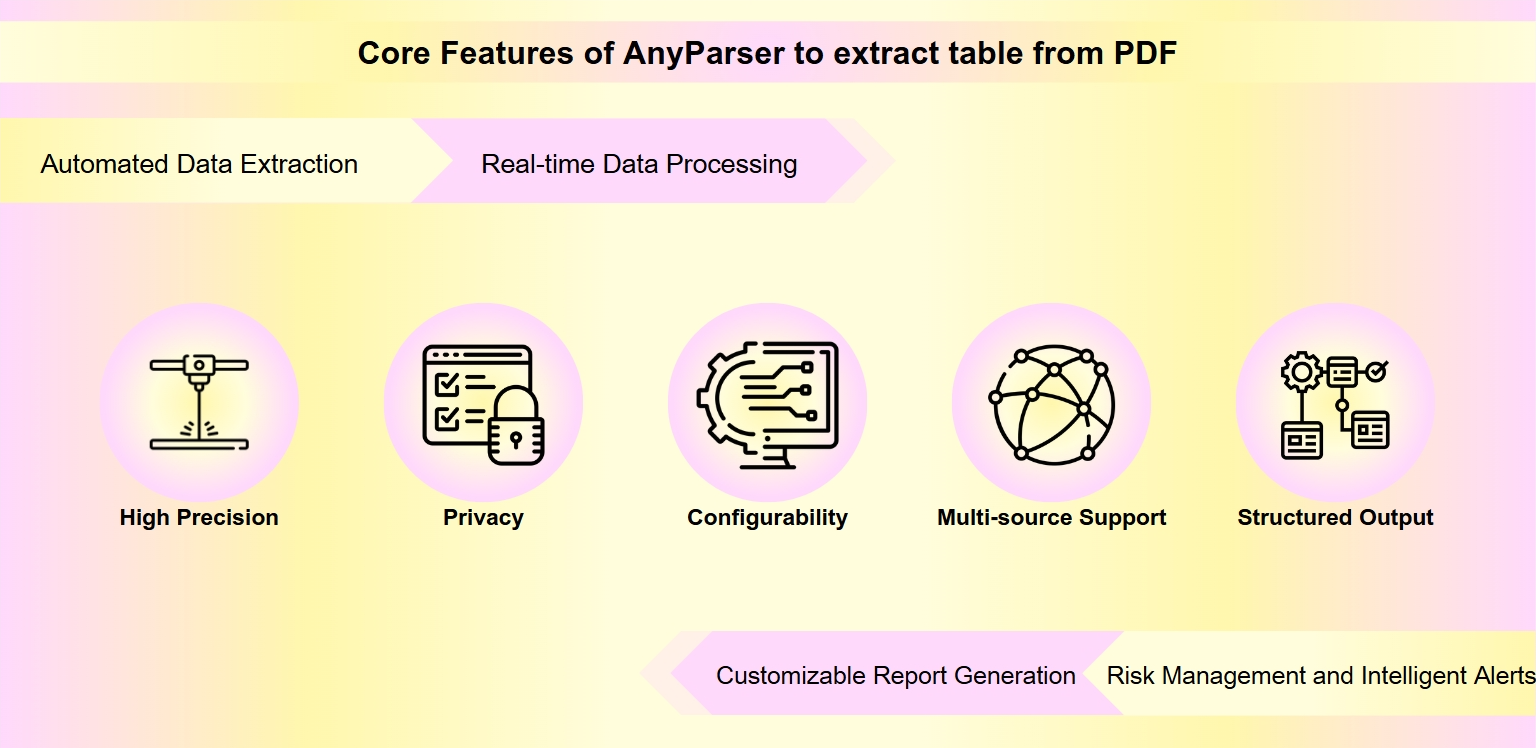
Klíčové funkce AnyParser pro extrakci tabulek z PDF
-
Vysoká přesnost: AnyParser je navržen tak, aby přesně kopíroval data tabulek z PDF do Excelu při zachování původního rozvržení a formátu, což zajišťuje přesnost při extrakci dat.
-
Ochrana soukromí: Zpracovává data lokálně, chrání uživatelské soukromí a citlivé informace, což je zásadní při extrakci dat z PDF.
-
Konfigurovatelnost: Uživatelé mohou definovat vlastní pravidla extrakce a formáty výstupu, což poskytuje flexibilitu při extrakci tabulek z PDF podle specifických požadavků.
-
Podpora více zdrojů: AnyParser je schopen extrahovat informace z různých nestrukturovaných datových zdrojů, včetně PDF, obrázků a grafů.
-
Strukturovaný výstup: Nástroj převádí extrahované informace do strukturovaných formátů, jako je Excel, což usnadňuje analýzu a zpracování.
Zjednodušení datových pracovních postupů s AnyParser: Automatizace, integrace a analýza
- Automatizovaná extrakce dat
- Zpracování dat v reálném čase
- Přizpůsobitelné generování reportů
- Řízení rizik a inteligentní upozornění
Jak AnyParser transformuje extrakci tabulek z PDF:
- Zjednodušený pracovní postup od PDF do Excelu
- Extrakce a zpracování dat v reálném čase
- Automatizované generování reportů pro vlastní poznatky
- Proaktivní řízení rizik a inteligentní upozornění
Často kladené otázky o extrakci tabulek z PDF pomocí modelů Vision Language
Jak se extrakce založená na VLM srovnává s tradičními metodami OCR?
Modely Vision Language (VLM) poskytují významná vylepšení oproti tradičním OCR pro extrakci tabulek z PDF. Na rozdíl od OCR VLM přesně rozluští složitá rozvržení, chápou kontextové nuance a snadno zvládají více jazyků.
Které typy dokumentů jsou nejvhodnější pro extrakci VLM?
VLM jsou obzvlášť zdatné při zpracování strukturovaných dokumentů, které obsahují tabulky, grafy a prvky smíšeného obsahu. Nástroje založené na VLM mohou zachovat struktury tabulek a přesně extrahovat data i z nízkokvalitních skenů nebo dokumentů se složitým vícejazyčným obsahem.
Je extrakce založená na VLM přesnější než ruční zadávání dat?
Ano, řešení založená na VLM, jako je AnyParser, výrazně překonávají ruční zadávání dat nebo tradiční OCR z hlediska přesnosti. Tyto nástroje využívají jak vizuální, tak kontextovou inteligenci, což může snížit chyby konverze až o 50 % při přechodu z PDF do Excelu nebo Google Sheets.
Mohou VLM zpracovávat formáty souborů jiné než PDF?
Rozhodně, pokročilé nástroje založené na VLM nejsou omezeny pouze na PDF. Jsou schopny extrahovat data z různých formátů, včetně obrázků, Word dokumentů, PowerPoint prezentací a skenovaných dokumentů.
Závěr
AnyParser poskytuje mocné, flexibilní a uživatelsky přívětivé řešení pro extrakci cenných informací z komplexních dokumentů. Ať už jste AI inženýr, datový vědec nebo uživatel z podniku, AnyParser vám může pomoci efektivně se orientovat v výzvách nestrukturovaných dat. Když se rozhodnete využít modely Vision Language pro extrakci tabulek z PDF, pamatujte, že úspěch spočívá v dobře strukturovaném přístupu. Implementací robustního předzpracování, přesné klasifikace dokumentů a důkladného postzpracování můžete využít plný potenciál VLM pro vaše potřeby extrakce dat.
Výzva k akci:
Pojďme pokračovat implementací těchto poznatků. Zvažte kontaktování odborníků na modely Vision Language, jako je tým AnyParser, abyste:
Vyzkoušeli AnyParser zdarma pro extrakci tabulek z PDF na https://www.cambioml.com/sandbox
Získali bezplatnou konzultaci o tom, jak mohou VLM zlepšit váš pracovní postup extrakce dat.
Využití plné síly modelů Vision Language vyžaduje využití zkušeností a osvědčených postupů specialistů na konverzi. Udělejte další krok tím, že se spojíte s lídry v oboru a urychlíte svůj přechod k automatizovanějšímu, přesnějšímu a informativnějšímu procesu extrakce dat.