Modely Vision Language (VLM) revolučním způsobem mění oblast analýzy dokumentů a řeší mnoho omezení tradičních systémů optického rozpoznávání znaků (OCR). Zatímco OCR bylo základní technologií pro digitalizaci textu z obrázků, čelí významným výzvám v komplexních scénářích. Patří sem problémy s přesností u nekvalitních obrázků, omezené porozumění kontextu, obtíže s mixovanými jazyky a neschopnost interpretovat vizuální prvky. VLM nabízejí slibné řešení kombinací pokročilého počítačového vidění s možnostmi zpracování přirozeného jazyka. Tento článek zkoumá, jak VLM překonávají nedostatky OCR a poskytují robustnější a univerzálnější řešení pro zpracování dokumentů v digitálním věku.
Co je OCR? Jaké jsou procesy OCR při analýze dokumentů?
Optické rozpoznávání znaků (OCR) je technologie, která umožňuje převod různých typů dokumentů, jako jsou skenované papírové dokumenty, PDF soubory nebo obrázky pořízené digitálním fotoaparátem, na editovatelná a vyhledávatelná data. Tento proces je zásadní při zpracování dokumentů a extrakci dat z PDF, protože umožňuje strojům rozpoznat tištěné nebo ručně psané znaky uvnitř digitálních obrázků.
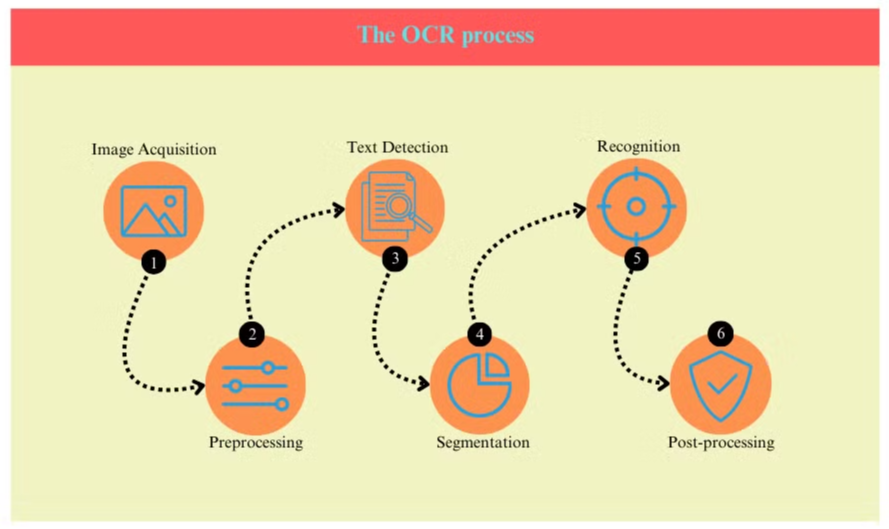
Proces OCR
Proces OCR obvykle zahrnuje několik kroků:
- Získání obrázku: Dokument je naskenován nebo vyfotografován, aby vznikl digitální obrázek.
- Předzpracování: Obrázek je vyčištěn, odstraněn šum a upraven jas a kontrast.
- Detekce textu: Systém identifikuje oblasti obsahující text v obrázku.
- Segmentace znaků: Jednotlivé znaky jsou izolovány v textových oblastech.
- Rozpoznání znaků: Každý znak je analyzován a porovnán s databází známých znaků.
- Post-processing: Rozpoznaný text je kontrolován na chyby pomocí jazykových a kontextových informací.
I když OCR výrazně zlepšilo schopnosti analýzy dokumentů, stále má omezení při práci s komplexními rozvrženími, nekvalitními obrázky a různými fonty. Zde přicházejí na řadu pokročilé technologie, jako jsou modely vision language, které zvyšují přesnost a porozumění při extrakci dat z obrázků a dokumentů.
Omezení tradiční technologie OCR
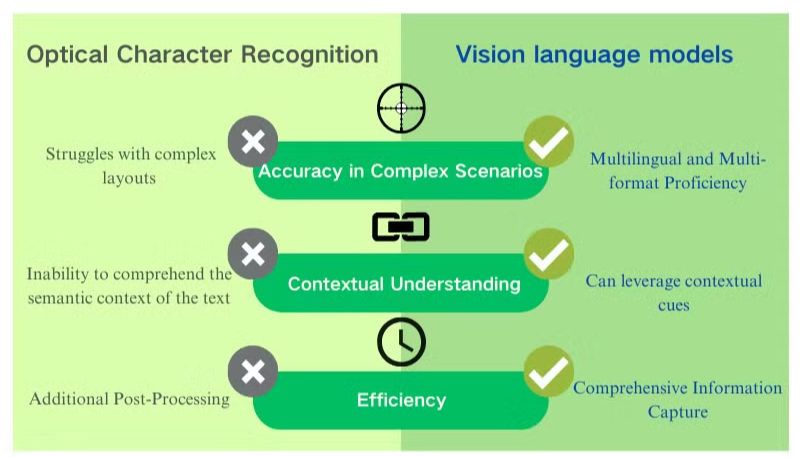
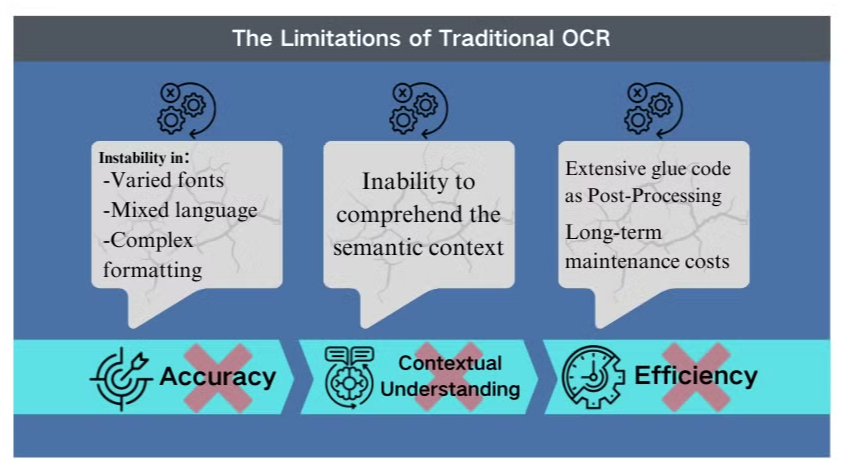
Výzvy s přesností v komplexních scénářích
Tradiční technologie optického rozpoznávání znaků (OCR), i když je užitečná pro základní extrakci textu, čelí významným překážkám při práci s komplikovanými rozvrženími dokumentů nebo nekvalitními obrázky. Tyto systémy často mají problémy s udržením přesnosti při zpracování dokumentů s různými fonty, mixovanými jazyky nebo složitým formátováním. Například OCR může selhávat při pokusu o extrakci dat z prezentací bohatých na obrázky nebo hustě formátovaných PDF.
Nedostatek porozumění kontextu
Jedním z nejvýraznějších omezení konvenčního OCR je jeho neschopnost pochopit sémantický kontext textu, který zpracovává. Tento nedostatek se stává obzvláště zřejmým ve scénářích vyžadujících jemnou interpretaci, jako jsou právní smlouvy nebo lékařské zprávy. Zaměření OCR na rozpoznávání znaků bez kontextového povědomí může vést k zásadním chybným interpretacím, zejména při práci s nejednoznačnými znaky nebo terminologií specifickou pro dané odvětví.
Neefektivnost při post-processingu
Omezení OCR často vyžadují rozsáhlé post-processingové úsilí. Tento dodatečný krok může významně zvýšit čas a zdroje potřebné pro zpracování dokumentů. Navíc tradiční OCR systémy obvykle selhávají při úkolu extrakce informací z grafů, tabulek nebo jiných netextových prvků, což dále komplikuje proces extrakce dokumentů. Tyto neefektivnosti zdůrazňují potřebu pokročilejších řešení, jako jsou modely vision language, které nabízejí komplexnější přístup k analýze dokumentů a extrakci dat.
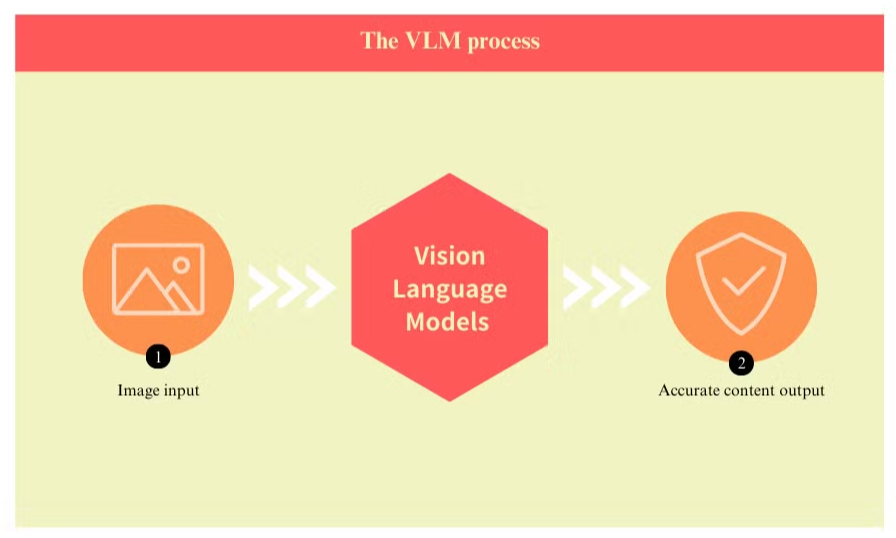
Co jsou modely Vision-Language a jak zlepšují OCR
Modely vision language představují významný pokrok v technologii zpracování dokumentů, řešící mnoho omezení tradičních systémů optického rozpoznávání znaků (OCR). Tyto pokročilé modely kombinují počítačové vidění se zpracováním přirozeného jazyka, aby současně pochopily vizuální i textové prvky dokumentů.
Zlepšená přesnost a porozumění kontextu
Na rozdíl od OCR, které má problémy s nekvalitními obrázky a složitými rozvrženími, modely vision language vynikají v interpretaci různorodých formátů dokumentů. Dokážou přesně extrahovat data z obrázků, PDF a dalšího vizuálního obsahu, i když čelí náročným scénářům. Tato zlepšená přesnost vychází z jejich schopnosti zohlednit celý kontext dokumentu, místo aby se zaměřovaly pouze na jednotlivé znaky nebo slova.
Komplexní extrakce dat
Modely vision language jdou nad rámec jednoduchého rozpoznávání textu a nabízejí komplexní schopnosti extrakce dat z PDF. Dokážou identifikovat a interpretovat tabulky, grafy a obrázky v dokumentech, přičemž zachovávají integritu složitých rozvržení. Tento holistický přístup k analýze dokumentů umožňuje nuancovanější a úplnější získávání informací, což výrazně zvyšuje užitečnost extrahovaných dat pro následné aplikace.
Multilingvní a multiformátová způsobilost
Jednou z klíčových výhod modelů vision language je jejich flexibilita při práci s více jazyky a formáty dokumentů. Na rozdíl od OCR systémů, které mohou mít problémy s nelatinskými písmy nebo mixovanými jazykovými dokumenty, tyto modely dokážou bez problémů zpracovávat obsah napříč různými jazyky a písmy, což je činí neocenitelnými pro globální potřeby zpracování dokumentů.
Klíčové výhody modelů Vision-Language pro porozumění dokumentům
Modely vision language nabízejí významné výhody oproti tradičnímu OCR při zpracování dokumentů a extrakci dat. Tyto systémy poháněné AI kombinují vizuální a textové porozumění, aby poskytly vynikající výsledky napříč různými typy dokumentů.
Zlepšená přesnost a porozumění kontextu
Modely vision language vynikají při práci s komplexními rozvrženími, nekvalitními obrázky a různorodými fonty. Na rozdíl od OCR, které má problémy s nejednoznačnými znaky, tyto modely využívají kontextové vodítka k přesné interpretaci textu. Tato schopnost dramaticky zlepšuje přesnost extrakce dat z PDF, zejména u dokumentů s komplikovanými strukturami nebo špatnou kvalitou obrázků.
Komplexní zachycení informací
Zatímco OCR se zaměřuje pouze na rozpoznávání textu, modely vision language dokážou extrahovat data z obrázků, tabulek a grafů. Tento holistický přístup zajišťuje, že během fáze zpracování dokumentů nejsou přehlíženy důležité informace. Zachycením textových i vizuálních prvků poskytují tyto modely úplnější porozumění obsahu dokumentů.
Multilingvní a multiformátová způsobilost
Modely vision language vykazují pozoruhodnou flexibilitu při zpracování dokumentů napříč různými jazyky a formáty. Dokážou bez problémů pracovat s mixovanými jazykovými dokumenty a nelatinskými písmy, čímž překonávají významné omezení tradičních OCR systémů. Tato všestrannost je činí neocenitelnými pro globální podniky, které pracují s různorodými typy dokumentů a jazyky.
Reálné aplikace umožněné VLM, kde OCR selhalo
Modely vision language revolučním způsobem mění zpracování dokumentů ve financích, lidských zdrojích a dalších sektorech, řešící kritická omezení tradičních OCR systémů. Tyto pokročilé AI modely transformují úsilí o digitální transformaci napříč průmyslovými odvětvími díky lepší přesnosti a porozumění kontextu.
Revoluce ve zpracování finančních dokumentů
Modely vision language transformují zpracování dokumentů ve financích, překonávají omezení tradičního OCR. Tyto pokročilé modely vynikají při extrakci dat z komplexních finančních výkazů, faktur a účtenek s komplikovanými rozvrženími. Na rozdíl od OCR dokážou pochopit kontext, přesně interpretovat nejednoznačné znaky (např. rozlišit mezi nulou a písmenem O) a mixované jazyky často přítomné v globálních finančních dokumentech.
Zlepšení HR operací díky inteligentní analýze dokumentů
V sektoru lidských zdrojů se modely vision language ukazují jako neocenitelné při extrakci dat z životopisů, zaměstnaneckých záznamů a hodnotících zpráv. Tyto modely dokážou pochopit sémantickou strukturu dokumentů, což umožňuje přesnější získávání a analýzu informací. Tato schopnost výrazně zefektivňuje procesy náboru a správu zaměstnaneckých dat, úkoly, kde OCR často selhává při práci s různými formáty a ručně psanými poznámkami.
Zlepšení dodržování předpisů a řízení rizik
Modely vision language jsou obzvláště účinné při dodržování předpisů a řízení rizik napříč financemi a HR. Dokážou extrahovat a interpretovat klíčové informace z regulačních dokumentů, smluv a politik s větší přesností než OCR. Tato vylepšená schopnost zpracování dokumentů zajišťuje lepší dodržování právních požadavků a efektivnější postupy hodnocení rizik.
Závěr
Závěrem lze říci, že modely pro práci s vizuálními a jazykovými daty představují významný pokrok v technologii zpracování dokumentů, řešící mnoho inherentních omezení tradičních OCR systémů. Spojením vizuálního a textového porozumění tyto pokročilé modely nabízejí vyšší výkon v široké škále náročných scénářů, od komplexních rozvržení přes smíšené jazyky až po nekvalitní obrázky. Jak organizace pokračují v digitalizaci svých operací a hledají efektivnější způsoby, jak získat hodnotu ze svých dokumentových úložišť, modely pro práci s vizuálními a jazykovými daty se stávají mocným nástrojem pro vývojáře i vedoucí technických týmů. Jejich schopnost chápat kontext, pracovat s různorodými formáty a poskytovat přesnější výsledky je staví do pozice klíčového prvku pro sofistikované RAG pipeline a podnikové vyhledávací možnosti, čímž nakonec posouvají iniciativy digitální transformace na novou úroveň.