Zajímalo vás někdy, co znamená zkratka OCR? Optické rozpoznávání znaků je mocná technologie, která převádí obrázky textu na strojově čitelná data. I když OCR nabízí obrovské výhody pro digitalizaci dokumentů a extrakci informací, není bez svých nevýhod. Při zkoumání této technologie je důležité pochopit jak její schopnosti, tak omezení. V tomto článku se dozvíte, co OCR znamená, a podíváte se na jeho potenciální nevýhody. Získáním komplexního porozumění optickému rozpoznávání znaků budete lépe vybaveni k tomu, abyste určili, zda a jak tuto technologii implementovat do svých pracovních postupů a projektů.
Co znamená OCR a co je OCR?
Co znamená OCR?
OCR znamená optické rozpoznávání znaků, technologii, která umožňuje počítačům rozpoznávat a převádět různé typy dokumentů. V jádru je OCR proces skenování tištěného nebo ručně psaného textu a jeho převodu na strojově kódovaný text. To umožňuje textu být snadno vyhledávatelným, editovatelným a přenositelným. Pochopení toho, co znamená OCR, je zásadní pro každého, kdo pracuje s technologiemi skenování dokumentů a rozpoznávání textu.
Co je OCR?
Pro ty, kteří nejsou obeznámeni s tímto termínem, je „co je OCR“ běžná otázka, která se vztahuje na optické rozpoznávání znaků, technologii, která umožňuje počítačům číst text z obrázků nebo skenovaných dokumentů.
OCR převádí tištěný nebo ručně psaný text na strojově čitelná data, čímž překonává propast mezi papírovými a digitálními formáty. Tato technologie využívá sofistikované algoritmy k detekci tvarů písmen, struktur slov a dokonce i celých vět. Tímto způsobem transformuje statické obrázky na editovatelné a vyhledávatelné textové soubory.
Technologie OCR je v zásadě založena na technologiích počítačového vidění a rozpoznávání vzorů. OCR zahrnuje skenování dokumentů nebo obrázků obsahujících text a použití pokročilých algoritmů k identifikaci a převodu textu do digitálního, editovatelného formátu. Jedním z klíčových momentů v historii technologie OCR byl rok 1974, kdy Ray Kurzweil vyvinul systém omni-font OCR, který dokázal rozpoznávat text prakticky v jakémkoli písmu. V průběhu let se OCR vyvinulo od jednoduchého porovnávání šablon k sofistikovanějším systémům.
Navzdory svým schopnostem čelí technologie OCR v současnosti určitým omezením. Mezi ně patří problémy s rozpoznáváním textu na obrázcích s nízkou kvalitou, obtížnost při zpracovávání složitých rozložení nebo pozadí a různá přesnost při práci s různými písmy, jazyky nebo rukopisy. Kromě toho mohou systémy OCR mít potíže s dokumenty, které mají barevná pozadí, jsou rozmazané nebo nakloněné, a s kurzívou.
Pochopení softwaru pro optické rozpoznávání znaků
Software pro optické rozpoznávání znaků je transformační technologie, která převádí různé typy dokumentů na editovatelná a vyhledávatelná data. Hraje klíčovou roli v digitalizaci našeho světa, což činí informace přístupnějšími a lépe spravovatelnými. Software OCR používá sofistikovaný proces k převodu obrázků textu na strojově čitelná data.
Jak funguje software OCR
1. Získání obrázku
Cesta OCR začíná zachycením obrázku dokumentu. To lze provést pomocí skeneru nebo digitálního fotoaparátu. Obrázek je poté převeden do digitálního formátu, který může počítač zpracovat.
2. Předzpracování a zlepšení obrázku
Druhý krok zahrnuje zlepšení kvality obrázku. Jakmile je obrázek získán, podrobuje se předzpracování, aby se zlepšila jeho kvalita pro lepší rozpoznání. Tento krok může zahrnovat úpravu kontrastu, jasu a ostrosti obrázku, stejně jako odstranění šumu nebo irelevantních prvků. Tento předzpracovací krok je zásadní pro dosažení přesných výsledků, zejména při práci s nízkokvalitními skeny nebo fotografiemi.
3. Detekce textu
Software OCR analyzuje předzpracovaný obrázek, aby detekoval oblasti, které obsahují text. Dělá to tím, že hledá vzory a tvary, které jsou charakteristické pro text, jako jsou řádky různých tlouštěk a výšek.
4. Segmentace znaků
Jakmile jsou detekovány textové oblasti, software rozkládá text na menší jednotky, jako jsou bloky, řádky, slova nebo dokonce jednotlivé znaky. Software OCR analyzuje obrázek pixel po pixelu, aby identifikoval vzory, které tvoří znaky. Rozkládá obrázek na menší segmenty, izoluje každý znak.
5. Rozpoznávání a extrakce textu
Software poté porovnává tyto izolované tvary s rozsáhlou databází známých vzorů znaků, aby určil, co každý znak představuje. Software extrahuje vlastnosti z znaků, jako je počet čar, křivek nebo úhlů. Tyto vlastnosti pomáhají OCR rozpoznávat a rozlišovat mezi různými znaky.
6. Post-processing
Po identifikaci znaků prochází systém OCR fází post-processing, kde opravuje případné chyby a formátuje text pro výstup. Opravený text je poté exportován do požadovaného formátu, jako je dokument Word nebo vyhledávatelný PDF.
Případové studie se softwarem pro optické rozpoznávání znaků
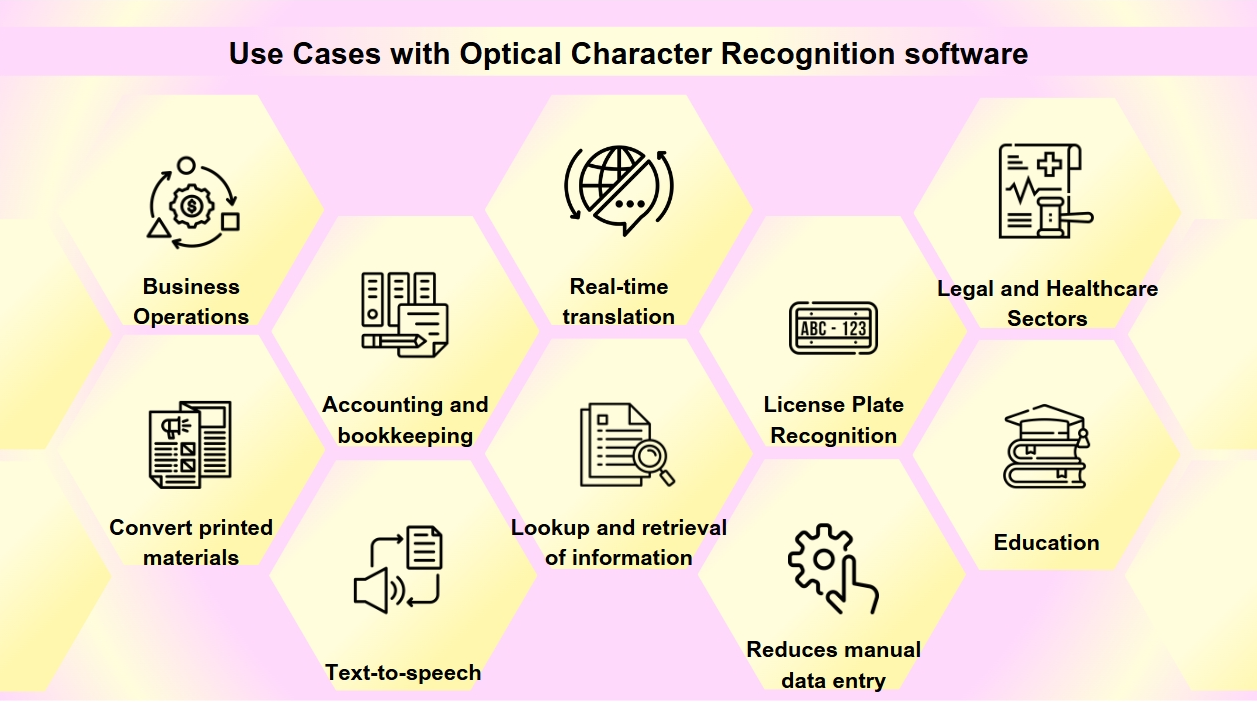
OCR se stal nezbytným nástrojem v digitální transformaci mnoha odvětví, zjednodušuje procesy a zlepšuje dostupnost a přesnost dat. Můžete se s OCR setkat častěji, než si uvědomujete. Od skenování vizitek po digitalizaci starých knih, OCR hraje klíčovou roli v různých odvětvích. Technologie OCR má široké spektrum aplikací:
-
Digitalizace dokumentů: OCR se používá k převodu tištěných materiálů, jako jsou staré knihy, noviny a historické dokumenty, do digitálních formátů, což je činí vyhledávatelnými a uchovává je pro budoucí generace.
-
Zpracování formulářů: Firmy využívají OCR k automatickému extrakci dat z formulářů, což snižuje manuální zadávání dat a zvyšuje efektivitu v různých sektorech, jako je finance a zdravotnictví.
-
Zpracování faktur: Technologie OCR dokáže číst text na fakturách a automaticky zadávat data do finančních systémů, což zjednodušuje účetnictví a knižní procesy.
-
Dostupnost: OCR umožňuje funkčnost text-to-speech, vytváří audio verze textu pro osoby se zrakovým postižením, čímž činí tištěné materiály přístupnějšími.
-
Mobilní aplikace: OCR je integrováno do aplikací pro úkoly, jako je skenování vizitek, rozpoznávání textu na fotografiích a usnadnění překladů v reálném čase.
-
Vyhledatelnost: OCR zvyšuje vyhledatelnost skenovaných dokumentů tím, že extrahuje text z obrázků nebo PDF, což umožňuje snadné vyhledávání a získávání informací.
-
Rozpoznávání registračních značek: Používá se pro správu parkování a dopravy, OCR dokáže rozpoznávat registrační značky, což umožňuje efektivní monitorování a vymáhání.
-
Podnikové operace: OCR zjednodušuje podnikové procesy automatizací zadávání dat z dokumentů, jako jsou faktury, účtenky a objednávky, a také urychluje nábor skenováním a zpracováním žádostí o zaměstnání a životopisů.
-
Právní a zdravotnické sektory: Právnické firmy používají OCR k digitalizaci spisů a právních dokumentů pro snadnější vyhledávání informací, zatímco poskytovatelé zdravotní péče ji využívají k převodu pacientských záznamů a lékařských formulářů na elektronické zdravotní záznamy (EHR), čímž zlepšují správu dat a péči o pacienty.
-
Vzdělávání: V vzdělávacím prostředí se OCR používá k vytváření digitálních učebnic a vzdělávacích materiálů, což zlepšuje dostupnost pro studenty s různými potřebami a podporuje inkluzivní vzdělávací prostředí.
Jak technologie OCR postupuje, nadále hraje zásadní roli v tom, aby informace byly přístupnější a efektivněji zpracovatelné v digitálním věku.
Nevýhody OCR: Omezení a nevýhody
Výzvy přesnosti
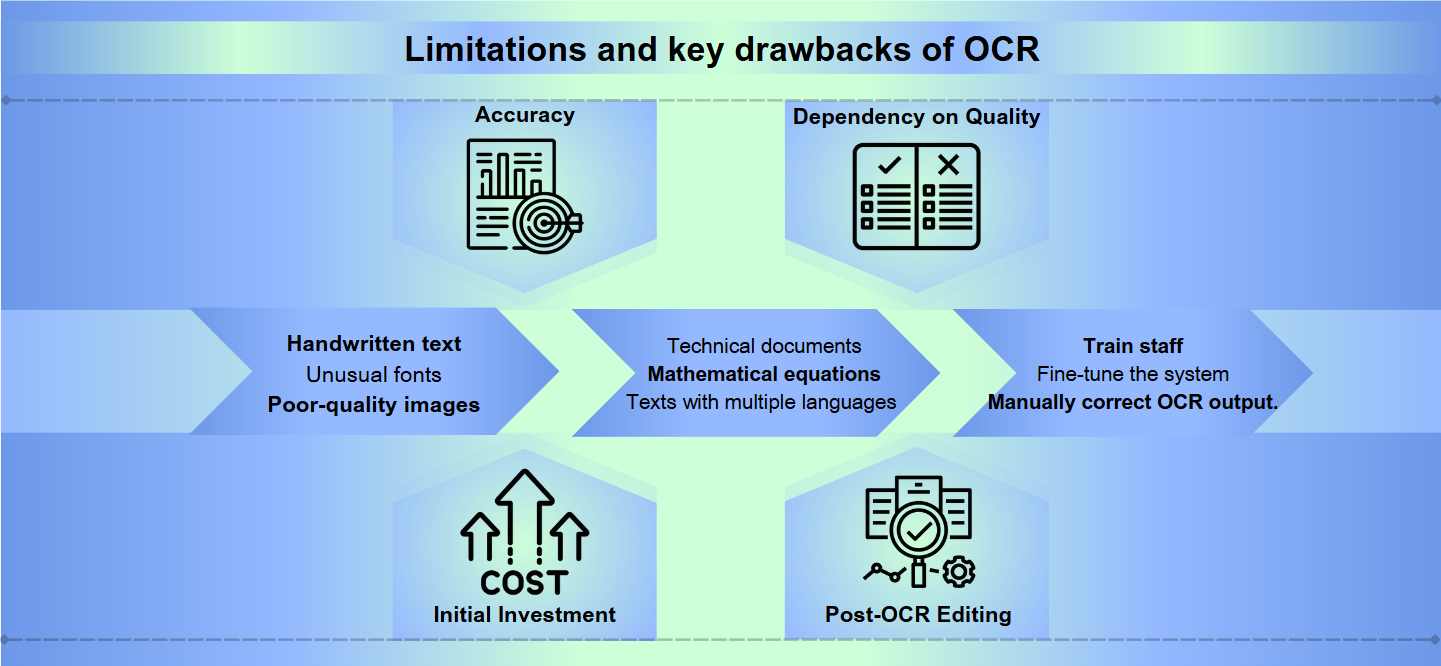
I když technologie optického rozpoznávání znaků (OCR) udělala velký pokrok, stále čelí významným překážkám při dosahování dokonalé přesnosti. Ručně psaný text, neobvyklá písma nebo obrázky špatné kvality mohou vést k nesprávným interpretacím a chybám. I drobné variace ve tvarech nebo velikostech znaků mohou zmást systémy OCR, což vede k nečitelnému výstupu, který vyžaduje manuální opravu.
Jazyková a formátová omezení
Většina řešení OCR vyniká se standardními jazyky a formáty, ale má potíže se specializovaným obsahem. Technické dokumenty, matematické rovnice nebo texty v několika jazycích mohou představovat významné výzvy. Kromě toho může OCR selhat, když se setká se složitými rozloženími, tabulkami nebo dokumenty s komplikovaným formátováním, což může vést ke ztrátě důležitých strukturálních informací.
Náročnost na zdroje
Implementace a údržba efektivního systému OCR může být náročná na zdroje. Vysoce kvalitní software OCR často přichází s vysokou cenou a hardware potřebný k zpracování velkých objemů dokumentů může být nákladný. Dále čas a úsilí potřebné k zaškolení personálu, doladění systému a manuální kontrole a opravě výstupu OCR mohou zatěžovat organizační zdroje.
Klíčové nevýhody OCR
-
Přesnost: Software OCR může mít potíže s přesností, zejména při práci s obrázky špatné kvality, složitými rozloženími nebo ručně psaným textem. Chyby se mohou pohybovat od nesprávného čtení znaků po vynechání celých částí textu.
-
Závislost na kvalitě: Účinnost OCR je silně závislá na kvalitě původního dokumentu. Bledý inkoust, rozmazání nebo pomačkaný papír mohou vést k nepřesným překladům.
-
Počáteční investice: Nastavení systému OCR může vyžadovat značné počáteční náklady, které zahrnují nejen software, ale také kompatibilní hardware, jako jsou skenery.
-
Úpravy po OCR: Často výstup z procesů OCR vyžaduje manuální revizi a opravu, což může být časově náročné.
Model jazykového vidění překonává omezení OCR
S pokrokem technologie se objevují inovativní řešení, která se snaží řešit nedostatky tradičního optického rozpoznávání znaků (OCR). Jedním z takových průlomů je model jazykového vidění (VLM), který kombinuje počítačové vidění a zpracování přirozeného jazyka, aby revolucionalizoval extrakci textu a jeho porozumění.
Vylepšené kontextové porozumění
VLM vynikají v chápání kontextu obklopujícího text, na rozdíl od izolovaného rozpoznávání znaků OCR. Analyzováním vizuálních prvků vedle textu mohou tyto modely interpretovat složitá rozložení, ručně psané poznámky a dokonce i částečně zakrytý text s pozoruhodnou přesností.
Vícejazyčné a multimodální schopnosti
Zatímco OCR často bojuje s různorodými jazyky a skripty, VLM prokazují impozantní všestrannost. Mohou bezproblémově zpracovávat více jazyků a dokonce interpretovat vizuální obsah, jako jsou diagramy nebo grafy, což poskytuje komplexnější porozumění dokumentům.
Adaptivní učení a kontinuální zlepšování
Na rozdíl od statických systémů OCR využívají VLM strojové učení k adaptaci a zlepšování v průběhu času. Jak se setkávají s novými daty a scénáři, tyto modely zdokonalují svůj výkon a stávají se stále zdatnějšími při zpracovávání různých typů a formátů dokumentů.
Překonáním omezení OCR otevírají modely jazykového vidění cestu k přesnějšímu, efektivnějšímu a inteligentnějšímu zpracování dokumentů napříč odvětvími.
Vyberte model jazykového vidění: Vyzkoušejte AnyParser
Na základě pokroků modelů jazykového vidění (VLM) se AnyParser objevuje jako sofistikované řešení, které překonává omezení tradiční technologie OCR. Vyvinutý týmem CambioML, AnyParser je mocný nástroj pro analýzu dokumentů, který využívá přesné a konfigurovatelné API k extrakci informací z různých nestrukturovaných datových zdrojů, jako jsou PDF, obrázky a grafy, a převádí je do strukturovaných formátů.
Technický základ a schopnosti
AnyParser je zakotven na robustním základu velkých jazykových modelů (LLM), což zajišťuje vysokou přesnost při extrakci textu, tabulek, grafů a rozložení z dokumentů. Vyniká svou schopností udržovat původní rozložení a formát, což je zvlášť výhodné pro dokumenty se složitými rozloženími nebo ty, které vyžadují zachování původní estetiky.
Ochrana soukromí a bezpečnost
Zdůrazňující ochranu soukromí uživatelů, AnyParser zpracovává data lokálně, čímž chrání citlivé informace. Tato funkce je významnou výhodou pro podniky a jednotlivce, kteří se zabývají důvěrnými daty.
Přizpůsobitelnost a flexibilita
Nabízející vysokou míru konfigurovatelnosti, AnyParser umožňuje uživatelům nastavit vlastní pravidla pro extrakci a definovat výstupní formáty, které vyhovují jejich specifickým potřebám. Tato přizpůsobivost z něj činí ideální nástroj pro široké spektrum aplikací, od AI inženýrství po finanční analýzu.
Závěr
Jak jste se dozvěděli, technologie OCR nabízí mocné schopnosti pro digitalizaci textu, ale není bez omezení. I když optické rozpoznávání znaků může dramaticky zlepšit efektivitu, musíte pečlivě zvážit potenciální nevýhody. Zvažte problémy s přesností, výzvy formátování a požadavky na zdroje před implementací řešení OCR. Nakonec rozhodnutí o využití OCR závisí na vašich specifických potřebách a okolnostech. Pochopením jak výhod, tak nevýhod můžete učinit informované rozhodnutí o tom, zda je OCR správné pro vaši organizaci. Jak se OCR nadále vyvíjí, zůstaňte informováni o nových vývojích, které mohou řešit současné nedostatky a odemknout ještě větší potenciál této transformační technologie.
Výzva k akci
Využijte sílu modelů jazykového vidění tím, že vyzkoušíte AnyParser zdarma k převodu vašich PDF do Google Sheets na https://www.cambioml.com/sandbox. Získejte bezplatnou konzultaci o tom, jak mohou VLM zlepšit váš pracovní postup extrakce dat.