En el ámbito de la gestión de datos, el análisis implica convertir el contenido—como texto, imágenes, tablas y metadatos—en un formato utilizable (por ejemplo, texto plano, datos estructurados o imágenes) que puede ser procesado o analizado posteriormente. Esto es especialmente evidente en el dominio del análisis de PDF, donde ingresamos al mundo del análisis, un proceso crucial que transforma información en bruto en datos estructurados y utilizables. Esta guía integral se adentra en las complejidades del análisis de PDF, elucidando su definición, el espectro de datos que puede extraer, los obstáculos que enfrenta, sus aplicaciones multifacéticas y la cornucopia de métodos disponibles para aprovechar su máximo potencial. Explorarás varios métodos de análisis, con un enfoque particular en el análisis de PDF y cómo herramientas como AnyParser se destacan entre la multitud.
Entendiendo el Analizador de PDF: ¿Qué es el análisis?
¿Qué es el análisis?: proceso meticuloso de captura de datos
En su esencia, el análisis de PDF se refiere al proceso de extraer e interpretar datos de archivos PDF (Formato de Documento Portátil). Dado que los PDF están diseñados principalmente para la visualización en lugar de almacenamiento de datos estructurados, el análisis implica convertir el contenido—como texto, imágenes, tablas y metadatos—en un formato utilizable (por ejemplo, texto plano, datos estructurados o imágenes) que puede ser procesado o analizado posteriormente. El análisis implica un análisis de alto nivel para identificar y recuperar elementos específicos dentro de un PDF, extendiéndose más allá del mero texto y las imágenes para abarcar fuentes, diseños, tablas y metadatos. Este proceso no es meramente una formalidad técnica, sino una necesidad en industrias tan diversas como finanzas, derecho, logística y salud, donde la reutilización de la información es primordial.
Datos que se pueden analizar desde PDFs
Los datos extraíbles de los PDFs son variados y extensos, incluyendo:
-
Párrafos de texto: Secuencias de palabras y caracteres.
-
Campos de datos individuales: Elementos individuales como fechas, números de seguimiento y nombres.
-
Datos tabulares: Información organizada en tablas y listas.
-
Imágenes: Contenido gráfico incrustado dentro del PDF.
-
Elementos avanzados: Encabezados, objetos, tablas de referencias cruzadas, tráileres y metadatos, que requieren herramientas de análisis más sofisticadas.
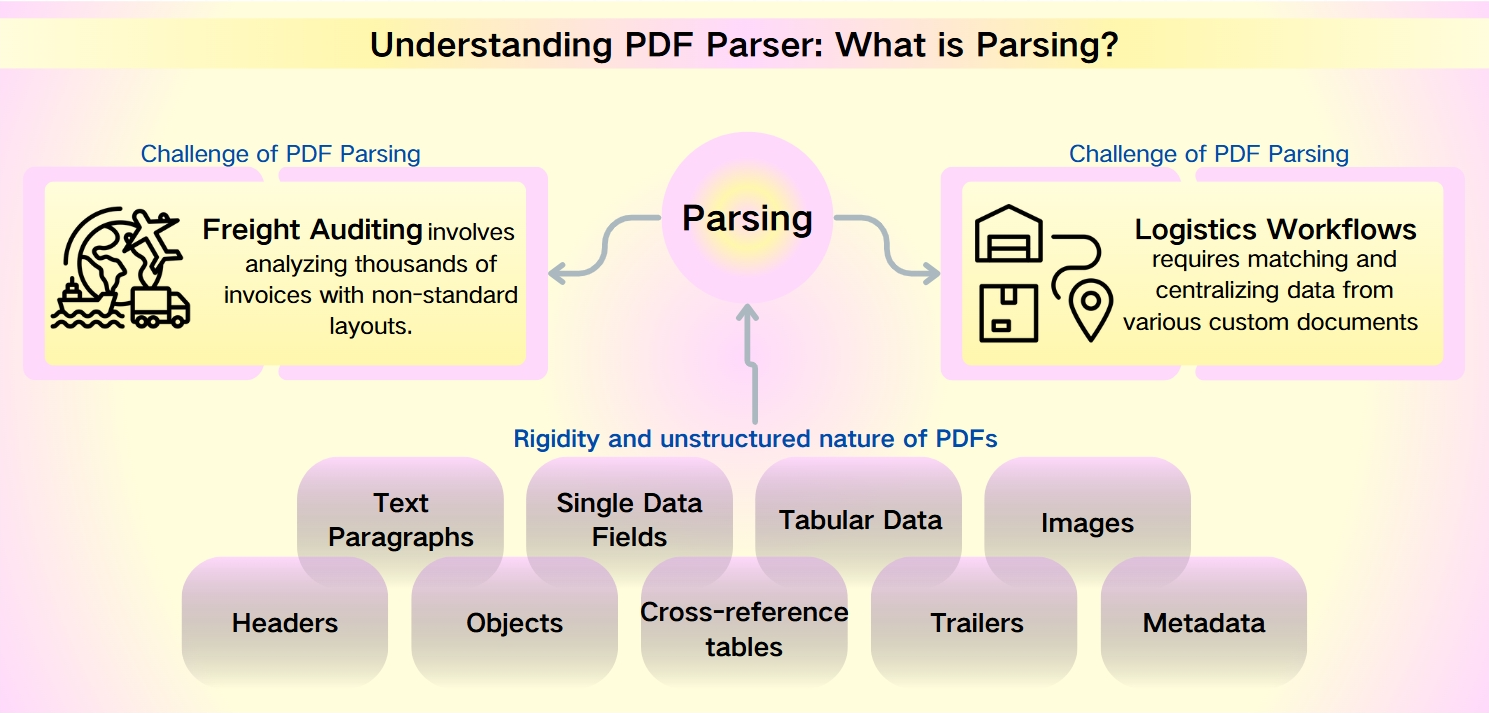
Desafíos del Análisis de PDF: naturaleza no estructurada de los metadatos de PDF
A pesar de la robustez de los PDFs—caracterizados por su seguridad, compatibilidad con dispositivos y tamaños de archivo compactos—la extracción de datos de ellos presenta un desafío formidable. La rigidez y la naturaleza no estructurada de los PDFs obstaculizan el análisis rápido y la recuperación de información. Esto es particularmente pronunciado en escenarios como la auditoría de fletes y los flujos de trabajo logísticos, donde los diseños no estándar y los volúmenes de datos complican la complejidad.
La auditoría de fletes implica analizar miles de facturas con diseños no estándar. Los flujos de trabajo logísticos requieren la coincidencia y centralización de datos de varios documentos personalizados como listas de empaque, facturas comerciales y conocimientos de embarque.
La Importancia del Análisis
El análisis juega un papel vital en varios campos, desde el desarrollo web hasta la captura de datos. Permite a las empresas extraer valiosos conocimientos de fuentes de datos no estructuradas, como documentos PDF, archivos HTML y datos XML. El análisis facilita:
-
Toma de decisiones mejorada a través de conocimientos basados en datos.
-
Mayor precisión y consistencia de los datos.
-
Procesamiento y análisis de datos optimizados.
-
Recuperación y almacenamiento de información eficientes.
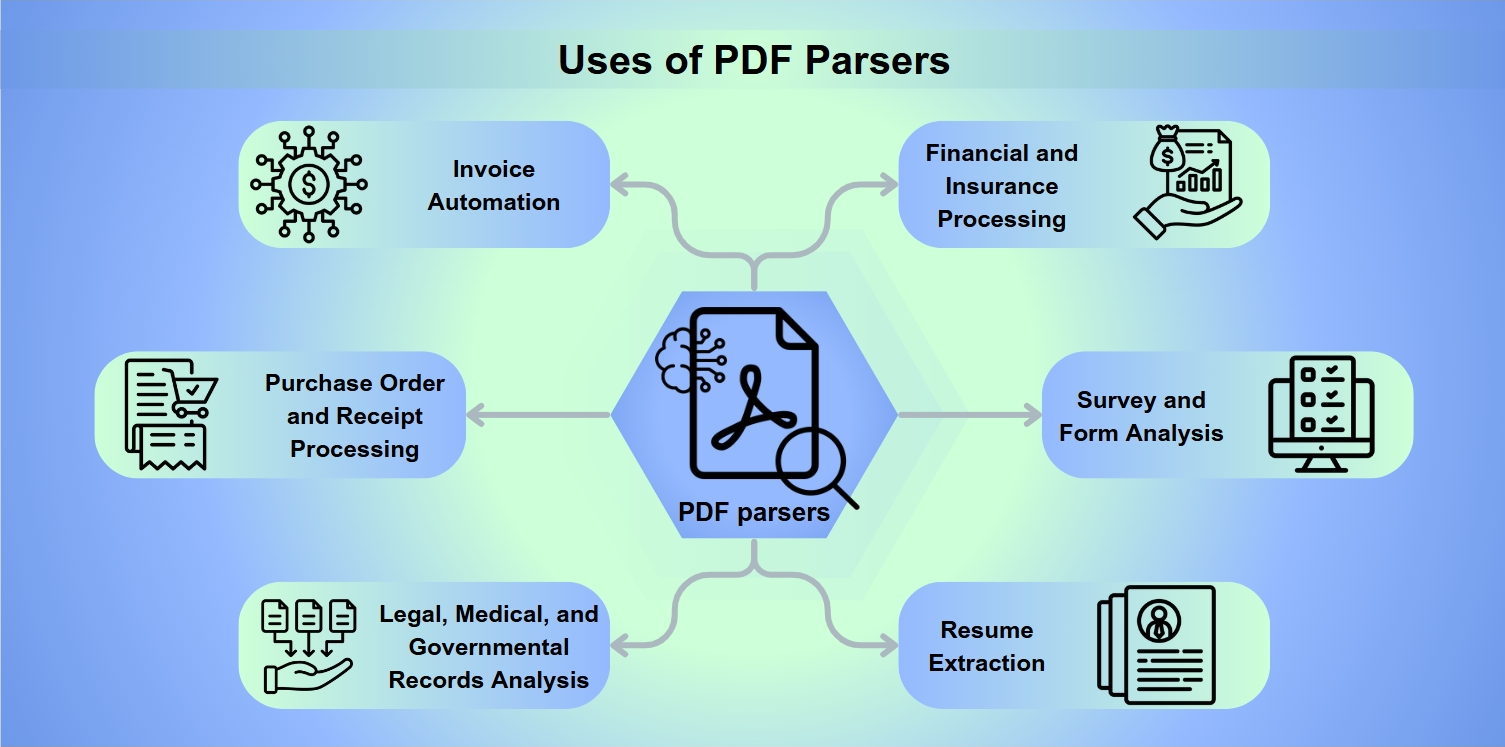
Usos de los Analizadores de PDF
Los analizadores de PDF son herramientas indispensables en una variedad de aplicaciones, incluyendo:
-
Automatización de Facturas: Optimización del procesamiento y pago de facturas.
-
Procesamiento de Órdenes de Compra y Recibos: Facilitación de reembolsos y reembolsos.
-
Análisis de Registros Legales, Médicos y Gubernamentales: Permitiendo una extracción de datos en profundidad para análisis.
-
Procesamiento Financiero y de Seguros: Evaluación de riesgos y análisis de balances.
-
Análisis de Encuestas y Formularios: Recopilación e interpretación de respuestas de formularios.
-
Extracción de Currículums: Ayudando a los reclutadores en la selección de candidatos.
Comparación de Diferentes Métodos de Análisis
Los métodos de análisis de datos han evolucionado significativamente con el tiempo. Los enfoques tradicionales de captura de datos a menudo dependen de expresiones regulares (regex) para extraer patrones específicos de texto. Si bien son potentes, las regex pueden volverse complejas y difíciles de mantener para tareas de análisis intrincadas. Otra técnica común es la manipulación de cadenas, que implica dividir y procesar texto basado en delimitadores o caracteres específicos. Estos métodos, aunque aún útiles en ciertos escenarios, pueden tener dificultades con formatos de datos no estructurados o inconsistentes.
El panorama del análisis de PDF es atendido por una variedad de métodos, cada uno con sus méritos y desventajas únicas:
-
Convertidores/Analizadores de PDF en línea: Como Zamzar y Smallpdf, ofrecen conveniencia y velocidad, pero están limitados en funcionalidad y pueden ser potencialmente inseguros.
-
Adobe Acrobat: Preserva la estructura y el formato, pero puede requerir ajustes manuales después de la conversión.
-
Copiar y Pegar: Proporciona control total, pero es laborioso y propenso a errores.
-
Plataformas Automatizadas: Las tecnologías modernas de análisis como AnyParser aprovechan el aprendizaje automático y el procesamiento del lenguaje natural (NLP) para manejar estructuras de datos más complejas.
Estos enfoques impulsados por IA pueden entender el contexto y la semántica, haciéndolos particularmente efectivos para analizar texto no estructurado o documentos con formatos variados. Algunos analizadores avanzados utilizan modelos de aprendizaje profundo para identificar y extraer información relevante con alta precisión, incluso de diseños de documentos previamente no vistos.
Cómo Realizar el Análisis de PDF: El Mejor Analizador de PDF Gratuito para Extraer Metadatos de PDF
Entendiendo los Metadatos de PDF
Los metadatos de PDF contienen información crucial sobre un documento, incluyendo su título, autor, fecha de creación y palabras clave. Extraer estos metadatos de manera eficiente es esencial para organizar, buscar y gestionar grandes colecciones de archivos PDF. Un analizador de PDF robusto puede agilizar este proceso, ahorrando tiempo y mejorando la productividad del flujo de trabajo.
Características Clave de los Mejores Analizadores de PDF
Los mejores analizadores de PDF gratuitos ofrecen una combinación de precisión, velocidad y versatilidad. Deben ser capaces de manejar varios formatos de PDF, incluyendo documentos escaneados y aquellos con diseños complejos. Busca analizadores que puedan extraer no solo metadatos básicos, sino también campos personalizados e información oculta. Además, los analizadores de primer nivel a menudo ofrecen opciones para la extracción de datos de PDF para procesamiento por lotes e integración con otros sistemas de software.
Características de AnyParser
AnyParser, desarrollado por CambioML, es particularmente notable debido a su precisión, privacidad y configurabilidad. La capacidad de AnyParser para manejar múltiples formatos de archivo, su interfaz fácil de usar y su escalabilidad lo convierten en una excelente opción para empresas de todos los tamaños. Además, su API permite una integración fluida en flujos de trabajo existentes, mejorando la eficiencia general de la gestión de documentos. Aquí hay algunas de las características clave que hacen de AnyParser una excelente opción para el análisis de PDF:
-
Precisión: AnyParser está diseñado para extraer con precisión texto, números y símbolos mientras mantiene el diseño y formato originales. Utiliza modelos de lenguaje avanzados para mejorar la comprensión del documento y la extracción de información, con una tasa de precisión hasta 2 veces mayor en comparación con los modelos OCR tradicionales.
-
Privacidad: Soporta tanto el análisis de datos en las instalaciones como en la nube, asegurando que la información sensible permanezca privada y segura.
-
Configurabilidad: Los usuarios pueden personalizar las reglas de extracción y los formatos de salida para adaptarse a necesidades específicas.
-
Soporte Multifuente: AnyParser admite una variedad de tipos de documentos, incluidos PDFs, imágenes y gráficos.
-
Salida Estructurada: La información extraída puede convertirse en formatos estructurados como Markdown, Excel o JSON, facilitando el procesamiento y análisis posterior.
-
Opciones de Implementación en la Nube: El SDK de AnyParser puede implementarse en la nube, en centros de datos o de forma privada, ofreciendo flexibilidad y escalabilidad.
-
Interfaz Amigable: La herramienta ofrece una API simple que permite realizar tareas complejas de análisis de documentos con solo unas pocas líneas de código.
-
Alto Rendimiento: Algoritmos optimizados aseguran un procesamiento rápido de un gran número de documentos, 5 veces más rápido que LLMs generalizados como GPT4o.
-
Soporte Comunitario: Como proyecto de código abierto, AnyParser se beneficia de una comunidad activa y da la bienvenida a contribuciones.
-
Cuota de Uso Gratuita: AnyParser ofrece una cuota de uso gratuita con cada cuenta, permitiendo a los usuarios probar las capacidades de la herramienta antes de comprometerse con un plan de pago.
-
Comentarios de Clientes: Los usuarios han elogiado a AnyParser por su alta precisión, preservación de la privacidad y eficiencia en la extracción de datos, con estudios de caso que muestran ahorros de tiempo significativos y mejora en la calidad de los datos.
Estas ventajas hacen de AnyParser un valioso extractor de datos de PDF para el análisis de documentos y la extracción de información, especialmente para usuarios empresariales que requieren alta precisión y seguridad. Con los avances tecnológicos en curso y el compromiso activo de la comunidad, AnyParser está preparado para desempeñar un papel cada vez más vital en el campo del análisis de documentos y la extracción de información.
Explicación Técnica de los Analizadores de PDF
El análisis de PDF comparte terreno conceptual con el scraping web, sin embargo, carece de la jerarquía estructurada del HTML. Mientras que los documentos web se analizan a través de etiquetas HTML accesibles, los PDFs presentan una matriz plana de caracteres y píxeles, exigiendo algoritmos y bibliotecas más sofisticadas para la extracción de datos.
Analizador de PDF vs Analizador de PDF en Python: Diferencias Clave
Un analizador de PDF es a menudo una herramienta independiente como extractor de datos de PDF o biblioteca diseñada específicamente para extraer datos de archivos PDF. Estos analizadores suelen ofrecer interfaces amigables y requieren un conocimiento mínimo de codificación. Por otro lado, los analizadores de PDF en Python son módulos o bibliotecas que se integran en scripts de Python, proporcionando más flexibilidad pero exigiendo experiencia en programación.
Los desarrolladores pueden ajustar el proceso de análisis, implementar análisis de texto avanzados e integrar sin problemas la extracción de datos de PDF en aplicaciones más amplias de Python. Los analizadores de PDF, aunque más limitados en personalización que los analizadores de PDF en Python, a menudo proporcionan características preconstruidas para casos de uso comunes, lo que los hace ideales para usuarios que necesitan resultados rápidos sin una programación extensa.
Ventajas de AnyParser con VLM para el Análisis de Datos
-
Alta Precisión: Los VLM de AnyParser aseguran que la extracción de datos mantenga alta fidelidad, incluso con diseños de documentos complejos.
-
Velocidad: Lidera en velocidad de conversión, mejorando la productividad al reducir el tiempo necesario para procesar documentos.
-
Amigable para el Usuario: AnyParser ofrece una interfaz sencilla, haciéndolo accesible para usuarios de todos los niveles.
-
Versatilidad: Más allá de los PDFs, AnyParser sirve como un potente convertidor de imágenes a Excel, soportando diversos tipos de documentos.
Conclusión
El análisis de PDF es más que un proceso técnico; es una puerta de entrada para transformar cómo las empresas manejan los datos. A pesar de los desafíos, la evolución de las soluciones de software ha hecho que sea más accesible que nunca. Ya sea que estés lidiando con el procesamiento de facturas o análisis de datos complejos, elegir el analizador de PDF adecuado es esencial. Se trata de encontrar la herramienta que ofrezca el equilibrio perfecto entre precisión, seguridad y eficiencia para empoderar tus iniciativas basadas en datos.
Comienza tu Prueba Gratuita Hoy
¿Listo para revolucionar tu procesamiento de documentos? Prueba AnyParser GRATIS sin necesidad de tarjeta de crédito en https://www.cambioml.com/sandbox. La prueba gratuita te permite procesar hasta 10 páginas por documento, con un tamaño máximo de archivo de 10 MB. Experimenta de primera mano cómo el analizador de PDF de AnyParser puede transformar tu enfoque hacia datos no estructurados y la extracción de documentos. No te pierdas esta oportunidad de mejorar tus capacidades de análisis de datos y optimizar tu flujo de trabajo con tecnología de IA de vanguardia.